内存管理1_物理内存分配

0、前言
主要分析内存的分配机制
https://blog.csdn.net/m0_65931372/article/details/126234314
1、内存结构
引自Linux 物理内存管理涉及的三大结构体之struct page
1.1 页 page
在linux kernel中,内存分配的最基本单位为页,也就是数据结构struct page,可以理解为每一个页对应着一个物理内存单元,通常为4KB。
下边是linux/mm_types.h定义的数据原型,在忽略一部分内容后,具体的代码如下。
struct page {
unsigned long flags; /* Atomic flags, some possibly
* updated asynchronously */
/*
* Five words (20/40 bytes) are available in this union.
* WARNING: bit 0 of the first word is used for PageTail(). That
* means the other users of this union MUST NOT use the bit to
* avoid collision and false-positive PageTail().
*/
union {
struct list_head lru;
/* See page-flags.h for PAGE_MAPPING_FLAGS */
struct address_space *mapping;
pgoff_t index; /* Our offset within mapping. */
/**
* @private: Mapping-private opaque data.
* Usually used for buffer_heads if PagePrivate.
* Used for swp_entry_t if PageSwapCache.
* Indicates order in the buddy system if PageBuddy.
*/
unsigned long private;
......
};
union { /* This union is 4 bytes in size. */
/*
* If the page can be mapped to userspace, encodes the number
* of times this page is referenced by a page table.
*/
atomic_t _mapcount;
.....
};
/* Usage count. *DO NOT USE DIRECTLY*. See page_ref.h */
atomic_t _refcount;
......
#if defined(WANT_PAGE_VIRTUAL)
void *virtual; /* Kernel virtual address (NULL if
not kmapped, ie. highmem) */
#endif /* WANT_PAGE_VIRTUAL */
......
} _struct_page_alignment;
其中各个域的含义如下:
- flags:表示当前页的状态。
- lru:当前页表中的lru(Least Recently Used,最近最少使用)链表,用来作为页替换的依据。
- mapping:作为page cache时page的具体地址(指向和这个页关联的addresss_space)。
- _mapcount:被映射的计数。
- _refcount:页的引用计数,表示当前这段内存也正在被多少进程引用。
- virtual:页在虚拟内存中的地址。
此外,可以把每一个物理页的基本单位是物理页帧,而每一个物理页帧都有自己的pfn物理页帧号,下边是物理页帧号和page以及物理页地址的转换关系
#define __pfn_to_page(pfn) (mem_map + ((pfn) - ARCH_PFN_OFFSET))
#define __page_to_pfn(page) ((unsigned long)((page) - mem_map) + \
ARCH_PFN_OFFSET)
1.2 区 zone
内存分区的原因在于,不同的硬件只能访问特定范围的内存,比如ISA总线的DMA就要求只能访问前16MB的内存。
因此基于硬件的限制,linux kernel内存整体分为如下几个区:(被定义在了include/linux/mmzone.h的enum zone_type中)
-
ZONE_DMA(0~16MB)
这个区域包含了适用于直接内存访问(Direct Memory Access, DMA)的内存。DMA是一种数据传输方式,可以在不经过CPU的情况下,直接在内存和外设之间传输数据。ZONE_DMA通常包含较低的物理地址空间,这是因为许多早期的外设只支持有限的地址范围进行DMA传输。
-
ZONE_DMA32
这个区域包含了适用于32位DMA设备的内存。这些设备可以访问较大的地址范围,通常高达4GB。ZONE_DMA32主要用于64位系统,因为在32位系统中,ZONE_NORMAL通常就足以满足DMA设备的需求。
-
ZONE_NORMAL(16MB~896MB)
Why Linux Kernel ZONE_NORMAL is limited to 896 MB?
这个区域包含了常规内存,可以被内核和用户空间进程使用。它不包括用于DMA的内存,因此可以避免与需要特定地址范围的DMA设备发生冲突。在32位系统中,ZONE_NORMAL通常包含了除ZONE_DMA之外的所有内存。
-
ZONE_HIGHEM(896MB~4GB)
这个区域包含了高端内存(high memory),即那些不能被内核直接映射到其线性地址空间的内存。在具有大量物理内存的32位系统上,内核地址空间可能不足以映射所有内存,因此需要将部分内存放入ZONE_HIGHMEM。64位系统通常不需要使用这个区域,因为它们具有足够大的地址空间。
-
ZONE_MOVABLE
这个区域包含了可移动内存。当系统需要连续的物理内存块时,内核可以将ZONE_MOVABLE中的页面迁移到其他区域,从而腾出连续的内存空间。这对于支持内存热插拔(hotplug)和大内存分配的系统非常有用。
-
CONFIG_ZONE_DEVICE
用于支持设备专用内存(device memory)。这种内存通常不是由通用内存子系统管理的,而是由特定的设备驱动程序管理。将设备内存纳入ZONE_DEVICE允许内核将这些设备内存纳入内存管理子系统,从而可以在需要时将其用于其他目的,设备专用内存的一个例子是显卡的显存。
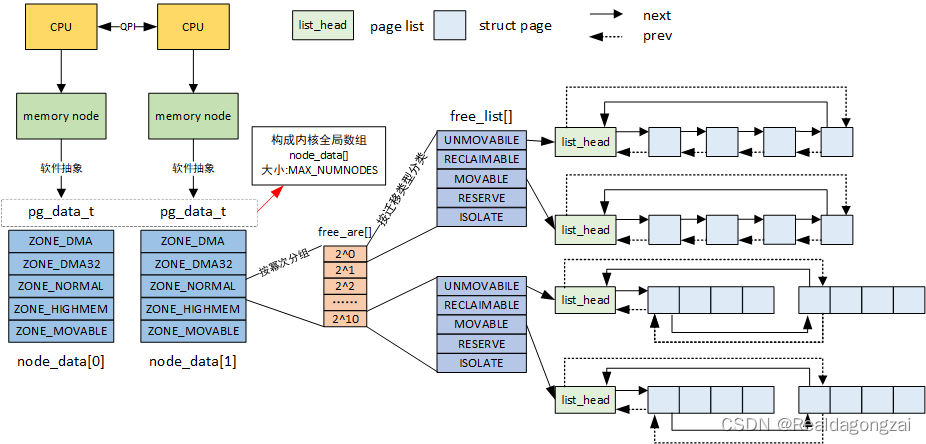
1.3 节点 node
对于NUMA架构的系统中,还会将内存的管理增加一个node节点,node节点是比zone更高级的管理层级。从下边的数据结构中可以看出,表示存放node的数据结构pglist_data中前几个域都是用来记录zone的。而对于uma的系统,相当于只有一个node节点的系统,故只有一个pglist_data数据结构。
对于常见的系统的来说,会存在numa0和numa1两个node。
但是区分于内存中的zone,node的结构在linux内是由软件区分的,而不是每一个node实际由自己的各个内存zone。
/*
* On NUMA machines, each NUMA node would have a pg_data_t to describe
* it's memory layout. On UMA machines there is a single pglist_data which
* describes the whole memory.
*
* Memory statistics and page replacement data structures are maintained on a
* per-zone basis.
*/
typedef struct pglist_data {
/*
* node_zones contains just the zones for THIS node. Not all of the
* zones may be populated, but it is the full list. It is referenced by
* this node's node_zonelists as well as other node's node_zonelists.
*/
struct zone node_zones[MAX_NR_ZONES]; // 管理区描述符的数组
/*
* node_zonelists contains references to all zones in all nodes.
* Generally the first zones will be references to this node's
* node_zones.
*/
struct zonelist node_zonelists[MAX_ZONELISTS]; // 页分配器所使用的数组
int nr_zones; /* 管理区的数目 */
#ifdef CONFIG_FLATMEM /* means !SPARSEMEM */
struct page *node_mem_map; // 节点中页描述符数组
......
#endif
#if defined(CONFIG_MEMORY_HOTPLUG) || defined(CONFIG_DEFERRED_STRUCT_PAGE_INIT)
......
#endif
unsigned long node_start_pfn; // 节点中第一个页框的下标
unsigned long node_present_pages; /* total number of physical pages */
unsigned long node_spanned_pages; /* total size of physical page
range, including holes */
int node_id; // 节点表示符
wait_queue_head_t kswapd_wait; // kswapd页换出守护进程的等待队列
......
struct task_struct *kswapd; /* 内核的kswapd进程描述符 */
int kswapd_order; // kswapd要创建的空闲块大小
......
#ifdef CONFIG_COMPACTION
......
#endif
......
#ifdef CONFIG_NUMA
/*
* node reclaim becomes active if more unmapped pages exist.
*/
unsigned long min_unmapped_pages;
unsigned long min_slab_pages;
#endif /* CONFIG_NUMA */
/* Write-intensive fields used by page reclaim */
CACHELINE_PADDING(_pad1_);
#ifdef CONFIG_DEFERRED_STRUCT_PAGE_INIT
......
#endif /* CONFIG_DEFERRED_STRUCT_PAGE_INIT */
#ifdef CONFIG_TRANSPARENT_HUGEPAGE
struct deferred_split deferred_split_queue;
#endif
#ifdef CONFIG_NUMA_BALANCING
......
#endif
......
/* Per-node vmstats */
struct per_cpu_nodestat __percpu *per_cpu_nodestats; // 用来描述node状态的数据
atomic_long_t vm_stat[NR_VM_NODE_STAT_ITEMS];
......
} pg_data_t;
在X86中,使用node_data来存储所有node中的pglist_data数据结构,其中nid就是表示numa的id。
extern struct pglist_data *node_data[];
#define NODE_DATA(nid) (node_data[nid])
2、页分配函数
2.1 请求page
alloc_pages使用来分配对应的物理页帧的函数,实际上大部分部分操作是不需要去分配物理内存的,因为物理内存已经分配好,直接从内存池中直接拿即可(后边会详细分析)。
#ifdef CONFIG_NUMA
struct page *alloc_pages(gfp_t gfp, unsigned int order);
......
#else
static inline struct page *alloc_pages(gfp_t gfp_mask, unsigned int order)
{
return alloc_pages_node(numa_node_id(), gfp_mask, order);
}
#endif
可以看到,对于NUMA的系统来说,在进行页面分配的时,会根据mempolicy执行三种不同的分配逻辑,而该策略主要是定义在当前运行的进程中。
-
MPOL_INTERLEAVE表示交错内存分配策略。在这种策略下,内核会在指定的一组NUMA节点间交错分配内存。这意味着连续的内存页会被分散到不同的NUMA节点上,从而实现内存访问负载的均衡。这种策略适用于访问模式为顺序访问的应用程序,例如流式处理(streaming)应用程序,因为它可以有效地利用多个节点的内存带宽,同时减小单个节点的内存访问压力。
-
MPOL_PREFERRED_MANY表示优先多节点内存分配策略。在这种策略下,内核会优先在指定的多个NUMA节点中分配内存。当内存需求无法在优先节点上得到满足时,内核会尝试在其他节点上分配内存。这种策略适用于对内存访问延迟敏感的应用程序,因为它可以确保内存分配尽可能地靠近优先的NUMA节点,从而减小内存访问延迟。
struct page *alloc_pages(gfp_t gfp, unsigned order)
{
struct mempolicy *pol = &default_policy;
struct page *page;
if (!in_interrupt() && !(gfp & __GFP_THISNODE))
pol = get_task_policy(current);
/*
* No reference counting needed for current->mempolicy
* nor system default_policy
*/
if (pol->mode == MPOL_INTERLEAVE)
page = alloc_page_interleave(gfp, order, interleave_nodes(pol));
else if (pol->mode == MPOL_PREFERRED_MANY)
page = alloc_pages_preferred_many(gfp, order,
policy_node(gfp, pol, numa_node_id()), pol);
else
page = __alloc_pages(gfp, order,
policy_node(gfp, pol, numa_node_id()),
policy_nodemask(gfp, pol));
return page;
}
EXPORT_SYMBOL(alloc_pages);
如果是一个不支持NUMA的系统,则通过一列调用,最终会调用到alloc_pages->alloc_pages_node->__alloc_pages_node->__alloc_pages,其实最终的差别就是只为了一个NUMA进行分配。
通过注释可以看到,alloc其实是从伙伴系统核心部分,它用于分配连续的物理内存页。
/*
* This is the 'heart' of the zoned buddy allocator.
*/
struct page *__alloc_pages(gfp_t gfp, unsigned int order, int preferred_nid,
nodemask_t *nodemask)
{
......
/*
* Apply scoped allocation constraints. This is mainly about GFP_NOFS
* resp. GFP_NOIO which has to be inherited for all allocation requests
* from a particular context which has been marked by
* memalloc_no{fs,io}_{save,restore}. And PF_MEMALLOC_PIN which ensures
* movable zones are not used during allocation.
*/
gfp = current_gfp_context(gfp); // 获取当前的请求页框的标志
alloc_gfp = gfp;
......
/* First allocation attempt */
page = get_page_from_freelist(alloc_gfp, order, alloc_flags, &ac); // 尝试直接从伙伴系统中拿到空闲页
if (likely(page))
goto out;
......
page = __alloc_pages_slowpath(alloc_gfp, order, &ac); // 伙伴系统中没找到则进行慢速分配
out:
......
return page;
}
EXPORT_SYMBOL(__alloc_pages);
请求页的标志位被定义在了include/linux/gfp_types.h
#define __GFP_RECLAIMABLE ((__force gfp_t)___GFP_RECLAIMABLE)
#define __GFP_WRITE ((__force gfp_t)___GFP_WRITE)
#define __GFP_HARDWALL ((__force gfp_t)___GFP_HARDWALL)
#define __GFP_THISNODE ((__force gfp_t)___GFP_THISNODE)
#define __GFP_ACCOUNT ((__force gfp_t)___GFP_ACCOUNT)
#define __GFP_RECLAIMABLE ((__force gfp_t)___GFP_RECLAIMABLE)
#define __GFP_WRITE ((__force gfp_t)___GFP_WRITE)
#define __GFP_HARDWALL ((__force gfp_t)___GFP_HARDWALL)
#define __GFP_THISNODE ((__force gfp_t)___GFP_THISNODE)
#define __GFP_ACCOUNT ((__force gfp_t)___GFP_ACCOUNT)
......
其用途主要是用来指明从哪里如何寻找空闲的页框,包括物理内存的区域,如__GFP_DMA含义是从DMA区获取空闲页,每一具体的定义在内核有详细的注释进行说明。
内核中实际上使用各种标志的组合进行内存分配,比较常用的几种具体flag如下
#define GFP_ATOMIC (__GFP_HIGH|__GFP_KSWAPD_RECLAIM)
#define GFP_KERNEL (__GFP_RECLAIM | __GFP_IO | __GFP_FS)
#define GFP_KERNEL_ACCOUNT (GFP_KERNEL | __GFP_ACCOUNT)
#define GFP_NOWAIT (__GFP_KSWAPD_RECLAIM)
#define GFP_NOIO (__GFP_RECLAIM)
#define GFP_NOFS (__GFP_RECLAIM | __GFP_IO)
#define GFP_USER (__GFP_RECLAIM | __GFP_IO | __GFP_FS | __GFP_HARDWALL)
#define GFP_DMA __GFP_DMA
#define GFP_DMA32 __GFP_DMA32
#define GFP_HIGHUSER (GFP_USER | __GFP_HIGHMEM)
#define GFP_HIGHUSER_MOVABLE (GFP_HIGHUSER | __GFP_MOVABLE | __GFP_SKIP_KASAN)
#define GFP_TRANSHUGE_LIGHT ((GFP_HIGHUSER_MOVABLE | __GFP_COMP | \
__GFP_NOMEMALLOC | __GFP_NOWARN) & ~__GFP_RECLAIM)
#define GFP_TRANSHUGE (GFP_TRANSHUGE_LIGHT | __GFP_DIRECT_RECLAIM)
而在分配的实际过程中,内核首先会尝试从伙伴系统的空闲页链表中分配内存页,如果失败了数进行慢速路径分配。这个过程可能会触发内存回收、内存压缩等操作,以便在内存紧张的情况下找到足够的空闲页。伙伴系统的部分后边详细分析,这里直接关注慢速分配路径。
具体的操作在代码中进行注释。代码很长,省略了一些代码,其中忽略了一些分配内存标志的检查,在状态不符合我们设定的状态描述符时,则会直接返回,例如我们标记了PF_MEMALLOC那么则不会尝试进行内存压缩分配。
static inline struct page *
__alloc_pages_slowpath(gfp_t gfp_mask, unsigned int order,
struct alloc_context *ac)
{
......
restart:
/*初始化变量,例如重试计数器、优先级等。*/
compaction_retries = 0;
......
/*
* 根据GFP标志和order调整alloc_flags
*/
alloc_flags = gfp_to_alloc_flags(gfp_mask, order);
......
if (alloc_flags & ALLOC_KSWAPD)
wake_all_kswapds(order, gfp_mask, ac); // 如果被标记了kswapd的回收
// 还是首先尝试从伙伴系统里直接拿空闲页
page = get_page_from_freelist(gfp_mask, order, alloc_flags, ac);
if (page)
goto got_pg;
/*
* 如果可以直接回收并且分配的order较高或者非MIGRATE_MOVABLE类型,
* 尝试直接压缩内存,然后分配
*/
if (can_direct_reclaim &&
(costly_order ||
(order > 0 && ac->migratetype != MIGRATE_MOVABLE))
&& !gfp_pfmemalloc_allowed(gfp_mask)) {
page = __alloc_pages_direct_compact(gfp_mask, order,
alloc_flags, ac,
INIT_COMPACT_PRIORITY,
&compact_result);
if (page)
goto got_pg;
/*
* 检查标记是不是高消耗的操作,例如透明大页的分配操作
*/
if (costly_order && (gfp_mask & __GFP_NORETRY)) {
if (compact_result == COMPACT_SKIPPED ||
compact_result == COMPACT_DEFERRED)
goto nopage;
compact_priority = INIT_COMPACT_PRIORITY;
}
}
retry:
/* Ensure kswapd doesn't accidentally go to sleep as long as we loop */
if (alloc_flags & ALLOC_KSWAPD)
wake_all_kswapds(order, gfp_mask, ac); // 在retry中再次执行一次kswapd
......
/* 尝试从空闲列表中分配内存页*/
page = get_page_from_freelist(gfp_mask, order, alloc_flags, ac);
if (page)
goto got_pg;
.......
/* 执行回收page,再分配 */
page = __alloc_pages_direct_reclaim(gfp_mask, order, alloc_flags, ac,
&did_some_progress);
if (page)
goto got_pg;
/* 执行压缩page,在分配 */
page = __alloc_pages_direct_compact(gfp_mask, order, alloc_flags, ac,
compact_priority, &compact_result);
if (page)
goto got_pg;
......
/*根据回收压缩的效果,判断是否要执行retry*/
if (should_reclaim_retry(gfp_mask, order, ac, alloc_flags,
did_some_progress > 0, &no_progress_loops))
goto retry;
if (did_some_progress > 0 &&
should_compact_retry(ac, order, alloc_flags,
compact_result, &compact_priority,
&compaction_retries))
goto retry;
/*
* 接下来就要执行oom了,再次之前要再确认下是不是有其他的zone或者set可以分配
*/
if (check_retry_cpuset(cpuset_mems_cookie, ac) ||
check_retry_zonelist(zonelist_iter_cookie))
goto restart;
/* 如果前边的操作都失败了,那么就会尝试执行oom清理一些进程来回收内存 */
page = __alloc_pages_may_oom(gfp_mask, order, ac, &did_some_progress);
if (page)
goto got_pg;
......
/* oom的时候会标记did_some_progress,那么此时我们就循环执行分配*/
if (did_some_progress) {
no_progress_loops = 0;
goto retry;
}
nopage:
/*
* 确认下是不是有其他的zone或者set可以分配内存
*/
if (check_retry_cpuset(cpuset_mems_cookie, ac) ||
check_retry_zonelist(zonelist_iter_cookie))
goto restart;
...... // 忽略了根据描述符进行的一些错误处理输出
/*在内存保留区域中分配内存*/
page = __alloc_pages_cpuset_fallback(gfp_mask, order, ALLOC_MIN_RESERVE, ac);
if (page)
goto got_pg;
cond_resched(); // 如果还是失败,那么首先会先让出cpu,后边尝试再次分配
goto retry;
}
fail:
warn_alloc(gfp_mask, ac->nodemask,
"page allocation failure: order:%u", order);
got_pg:
return page;
}
2.3 释放page
内核中有几个函数用于释放分配好的物理页框
__free_pagesfress_pages__free_pagefree_page
不带s的api主要是释放单独的页面,而带s则是释放连续的page。
fress_pages则会调用到__free_pages,它将连续的内存页归还给伙伴系统(buddy allocator),以便在后续的内存分配中重复使用这些内存页。
void __free_pages(struct page *page, unsigned int order)
{
/* get PageHead before we drop reference */
int head = PageHead(page);
if (put_page_testzero(page)) // 递减page的引用计数
free_the_page(page, order); // 将page还给伙伴系统
else if (!head)// 如果不是页的头部,则循环回收复合页其他页
while (order-- > 0)
free_the_page(page + (1 << order), order);
}
EXPORT_SYMBOL(__free_pages);
值得说的是PageHead(page)宏来检查给定的page是否为复合页(compound page)的头部。将结果存储在head变量中。复合页是一种用于表示较大连续内存块的机制,它将多个连续的物理页组合成一个逻辑上的大页。
在具体释放的过程中,还会区分是不是per_cpu页
static inline void free_the_page(struct page *page, unsigned int order)
{
if (pcp_allowed_order(order)) /* Via pcp? */
free_unref_page(page, order); // 释放per_cpu页给CPU cache
else
__free_pages_ok(page, order, FPI_NONE); // 释放正常页
}
接下来就会遍历循环order变量,将page换个伙伴系统,具体详细的部分我们后边分析伙伴系统时进一步讨论。



