内存管理4-页面回收

1、概述
内核中的内存页面回收算法叫做PFRA(page frame reclaiming algorithm)。
其那边我们分析了物理页内存的管理和申请流程,但是如果内存一直不进行回收,那么系统中可用的物理内存很快就会耗尽,因此PFRA的作用就是在合适的时机找到合适的page进行回收,从而保证其他进程在新申请内存时有内存可用。
所以PFRA就有如下几个核心点需要实现:
-
什么样的页可以回收
-
什么时候回收
-
怎么安全的回收页
2、目标页
我们分析过,linux kernel中使用伙伴系统来管理物理页框,那么我们回收页框的最终归宿就是加入到伙伴系统中,并提供给系统中的所有进程使用。因此我们在回收页的时候,至少伙伴系统中已经存在的页是不需要回收的。
2.1-不可回收页
-
空闲页
也就是已经在
伙伴系统中的页,如前边分析,我们回收页的最终去向是伙伴系统,因此已经在free_list中的页是不无须也无法再回收的。 -
保留页
被标记为
PG_reserved,一般这些用都是用来重要部分的内存,例如内核镜像位置、驱动的重要区域* PG_reserved is set for special pages. The "struct page" of such a page * should in general not be touched (e.g. set dirty) except by its owner. * Pages marked as PG_reserved include: * - Pages part of the kernel image (including vDSO) and similar (e.g. BIOS, * initrd, HW tables) * - Pages reserved or allocated early during boot (before the page allocator * was initialized). This includes (depending on the architecture) the * initial vmemmap, initial page tables, crashkernel, elfcorehdr, and much * much more. Once (if ever) freed, PG_reserved is cleared and they will * be given to the page allocator. * - Pages falling into physical memory gaps - not IORESOURCE_SYSRAM. Trying * to read/write these pages might end badly. Don't touch! * - The zero page(s) * - Pages not added to the page allocator when onlining a section because * they were excluded via the online_page_callback() or because they are * PG_hwpoison. * - Pages allocated in the context of kexec/kdump (loaded kernel image, * control pages, vmcoreinfo) * - MMIO/DMA pages. Some architectures don't allow to ioremap pages that are * not marked PG_reserved (as they might be in use by somebody else who does * not respect the caching strategy). * - Pages part of an offline section (struct pages of offline sections should * not be trusted as they will be initialized when first onlined). * - MCA pages on ia64 * - Pages holding CPU notes for POWER Firmware Assisted Dump * - Device memory (e.g. PMEM, DAX, HMM) -
锁定页
也就是被标记为
PG_locked的页,锁定页通常是正在使用的页,比如正在写入或者读取的page cache页,这种页由于正在使用中,所以也不能进行操作。下边这些页由于是在内核态,涉及到操作系统本身的运行,因此也是不可以回收的
-
内核动态分配页
也就是用kmalloc申请的内存和slab中已经分配的内存(被标记为
PG_slab)。 -
进程内核态堆栈页
也就是
task_struct对应的内存空间,释放了就找不到进程对应的信息了。 -
内存锁定页
2.2-可操作的页
可以操作的页大致分为三类
2.2.1-可回收页
如下这些也是可以保存在swap空间后,进行回收的页面。准确的说这些页面不算是回收页面,而算是在内存不足的情况进行交换。
- 匿名页
匿名页是指不直接关联到任何文件系统上的文件的内存页面,通常就是有malloc申请出来的页,用于匿名页的标记主要是
内核中有api去识别页是否是匿名页,可以看到识别的方式就是检查这个页是否为PAGE_MAPPING_ANON
static __always_inline bool PageAnon(struct page *page)
{
return folio_test_anon(page_folio(page));
}
static __always_inline bool folio_test_anon(struct folio *folio)
{
return ((unsigned long)folio->mapping & PAGE_MAPPING_ANON) != 0;
}
- Tmpfs文件系统的映射页
2.2.2-可同步页
如下的页在内存紧张时,可以执行sync操作把页的内容写回到磁盘中,再进行回收利用,下边这些可以被回收的页也被叫做脏页。
- 映射页
- 存有磁盘文件数据且在页高速缓存中的页
- 块设备缓冲区页
- 某些磁盘高速缓存的页(如索引节点高速缓存)
2.2.3-可丢弃页
下列页可以直接drop掉,而无须同步或者交换工作。
-
内存高速缓存中的未使用页(如slab分配器高速缓存)
分配在slab中,但是还空闲没有被使用的部分,可以被系统通过slab分配器主动回收。
-
目录项高速缓存的未使用页
用于缓存文件系统中的目录项(dentry)。目录项表示了文件系统中文件和目录的结构。
- 未使用的目录项页: 这些页包含了不再被文件系统访问的目录项。当这些目录项变得不活跃或无效时,存储它们的页可以被视为可丢弃。
- 无需同步或交换: 这些目录项页通常不包含未写回的数据,因此可以在不进行同步或交换操作的情况下直接被丢弃。
3、回收的基本情形
3.1-回收入口
分析完有哪些页可回收或者说可以由内核中的PFRA算法进行操作,那记下来继续分析下什么在什么情景下,内核会执行内存回收的工作流程:
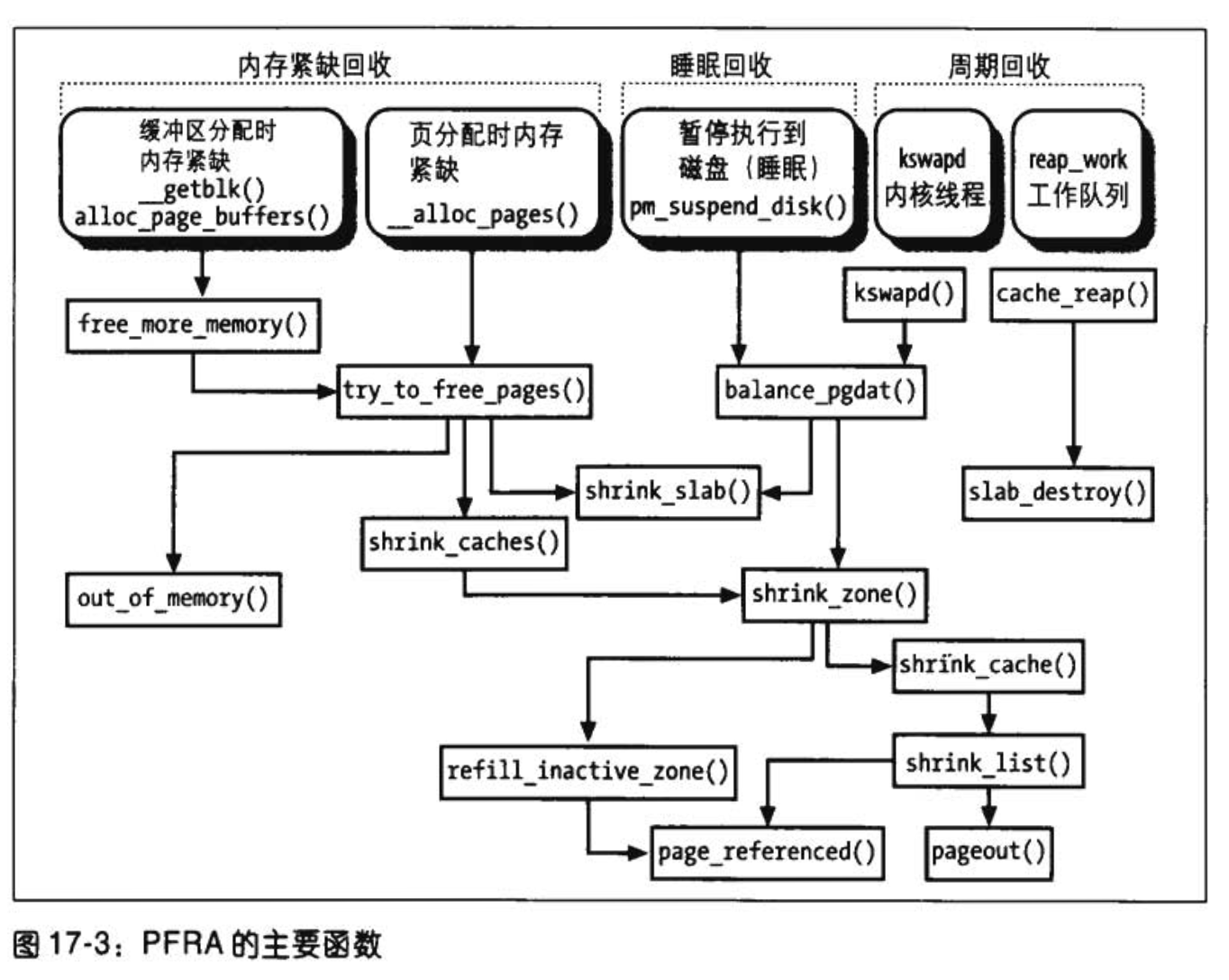
上图摘自《ULK》,这里细分出了三种流程(虽然里边大部分流程已经在最新的内核中见不到了):
-
内存紧缺时回收
内核在接收到内核态kmalloc、vmalloc分配内存时,如果发现此时内存已经不足,那么就会主动开始回收内存。
并且这里如果系统发现实在回收不到内存,会执行
OOM操作,kill不重要的进程,从而释放他的所有页表,这部分逻辑可以在__alloc_pages中可以看到,我们后边详细分析。 -
睡眠回收(这种貌似在最新的内核中已经找不到)
在硬盘执行休眠时,会主动释放一部分内存
-
周期回收
这里比较为人常了解就是主要靠
kswapd线程定期回收内存。另外就是还存在一个内核主动挂载回收slab的线程,也就是叫做
reap_work的一个内核工作队列INIT_DEFERRABLE_WORK(reap_work, cache_reap); /** * cache_reap - Reclaim memory from caches. * @w: work descriptor * * Called from workqueue/eventd every few seconds. * Purpose: * - clear the per-cpu caches for this CPU. * - return freeable pages to the main free memory pool. * * If we cannot acquire the cache chain mutex then just give up - we'll try * again on the next iteration. */ static void cache_reap(struct work_struct *w)
3.2-lru
内核中使用了一个叫做lru的功能,用来标识哪一个page用来回收,在比较老的版本上,每个zone上有active与inactive两种lru链表,分别用来记录最常使用的page和最不常使用的page,并且同时区分匿名页和文件页(优先回收文件页)。
所以最终会形成如下结构
enum lru_list {
LRU_INACTIVE_ANON = LRU_BASE,
LRU_ACTIVE_ANON = LRU_BASE + LRU_ACTIVE,
LRU_INACTIVE_FILE = LRU_BASE + LRU_FILE,
LRU_ACTIVE_FILE = LRU_BASE + LRU_FILE + LRU_ACTIVE,
LRU_UNEVICTABLE,
NR_LRU_LISTS
};
但是在新版的内核中,lru功能被mg-lru(Multi-generational LRU)替代,简单的说,新的LRU区分很详细的世代,从而更加准确的对内存页的使用情况进行了划分。
所以传统分析的各种交换方法,在当前的内核已经找不到了,只不过原理还是类似的。
有机会,会详细分析一下mg-lru的功能。
但是在5.4.0017里还是可以看到上述lru链表项在不同node和zone上数值的统计
# cat /proc/zoneinfo
Node 0, zone Normal
pages free 1183154
min 9231
low 12572
high 15913
spanned 3407872
present 3407872
managed 3341816
protection: (0, 0, 0, 0, 0)
nr_free_pages 1183154
nr_zone_inactive_anon 661922
nr_zone_active_anon 21664
nr_zone_inactive_file 347328
nr_zone_active_file 992845
nr_zone_unevictable 0
......
3.3-水位线
内存在回收的时候,判断回收多少、要不要回收的一个依据就是水位线,这个被定义在每个zone的结构体里的一个数组结构里
struct zone {
/* Read-mostly fields */
/* zone watermarks, access with *_wmark_pages(zone) macros */
unsigned long _watermark[NR_WMARK];
......
}
并且通过下列宏定义进行访问
#define min_wmark_pages(z) (z->_watermark[WMARK_MIN] + z->watermark_boost)
#define low_wmark_pages(z) (z->_watermark[WMARK_LOW] + z->watermark_boost)
#define high_wmark_pages(z) (z->_watermark[WMARK_HIGH] + z->watermark_boost)
其中的定义的含义大致是:
- 低水位线(low watermark):当可用内存高于低水位线时,内核认为内存充足,不需要进行内存回收。内核会尽量保持可用内存高于低水位线。
- 高水位线(high watermark):当可用内存低于高水位线时,内核认为内存压力较大,需要进行内存回收。内核会尝试回收足够的内存,使可用内存达到高水位线。
- 最小水位线(min watermark):当可用内存低于最小水位线时,内核认为内存极度紧张,需要立即进行紧急内存回收。在这种情况下,内核会采取更激进的内存回收策略,以释放更多内存。
4-回收方法
4.1-申请时主动回收
在__alloc_pages->__alloc_pages_slowpath中会有流程,在申请不到可用内存后,会主动调用几种方法进行处理
/* Try direct reclaim and then allocating */
page = __alloc_pages_direct_reclaim(gfp_mask, order, alloc_flags, ac,
&did_some_progress);
......
/* Try direct compaction and then allocating */
page = __alloc_pages_direct_compact(gfp_mask, order, alloc_flags, ac,
compact_priority, &compact_result);
......
/* Reclaim has failed us, start killing things */
page = __alloc_pages_may_oom(gfp_mask, order, ac, &did_some_progress);
4.1.1-直接同步回收
通过__perform_reclaim执行回收
static unsigned long
__perform_reclaim(gfp_t gfp_mask, unsigned int order,
const struct alloc_context *ac)
{
unsigned int noreclaim_flag;
unsigned long progress;
cond_resched();
/* We now go into synchronous reclaim */
cpuset_memory_pressure_bump(); // 增加内存压力计数,表示当前正在进行内存回收操作
fs_reclaim_acquire(gfp_mask); // 获取文件系统回收锁,防止在进行回收操作时发生竞争条件
noreclaim_flag = memalloc_noreclaim_save(); // 保存当前的内存分配状态,并设置不进行回收的标志,以防止在回收过程中递归调用回收
progress = try_to_free_pages(ac->zonelist, order, gfp_mask,
ac->nodemask); // 尝试释放指定数量的内存页
memalloc_noreclaim_restore(noreclaim_flag); // 恢复之前保存的内存分配状态
fs_reclaim_release(gfp_mask);
cond_resched();
return progress;
}
最终会调用do_try_to_free_pages->shrink_zones
/*
* This is the direct reclaim path, for page-allocating processes. We only
* try to reclaim pages from zones which will satisfy the caller's allocation
* request.
*
* If a zone is deemed to be full of pinned pages then just give it a light
* scan then give up on it.
*/
static void shrink_zones(struct zonelist *zonelist, struct scan_control *sc)
{
......
for_each_zone_zonelist_nodemask(zone, z, zonelist,
sc->reclaim_idx, sc->nodemask) { // 遍历zone
......
/*尝试从超过软限制的内存 cgroup 中回收内存页*/
nr_soft_reclaimed = mem_cgroup_soft_limit_reclaim(zone->zone_pgdat,
sc->order, sc->gfp_mask,
&nr_soft_scanned);
sc->nr_reclaimed += nr_soft_reclaimed;
sc->nr_scanned += nr_soft_scanned;
/* need some check for avoid more shrink_zone() */
}
......
shrink_node(zone->zone_pgdat, sc); //从zone_pgdat中会回收页
}
......
}
而在shrink_node中,会优先执行lru_gen_shrink_node回收内存。并且会区分如果是kswap线程的话就再对应的周期回收逻辑。kswap的逻辑后续周期回收再进一步分析。
static void lru_gen_shrink_node(struct pglist_data *pgdat, struct scan_control *sc)
{
......
if (!sc->may_writepage || !sc->may_unmap)
goto done;
lru_add_drain();
......
if (current_is_kswapd())
sc->nr_reclaimed = 0;
if (mem_cgroup_disabled())
shrink_one(&pgdat->__lruvec, sc);
else
shrink_many(pgdat, sc);
......
}
而shrink_many最终也会调用到shrink_one
static int shrink_one(struct lruvec *lruvec, struct scan_control *sc)
{
......
mem_cgroup_calculate_protection(NULL, memcg);
// 根据水位区分lru的状态
if (mem_cgroup_below_min(NULL, memcg)) // 如果目前memcg中内存已经低于回收下限
return MEMCG_LRU_YOUNG; // 就标记为young lru,也就是不要回收
if (mem_cgroup_below_low(NULL, memcg)) { // 如果低于回收low
/* see the comment on MEMCG_NR_GENS */
if (seg != MEMCG_LRU_TAIL)
return MEMCG_LRU_TAIL; // 则会返回老年lru,也即是可以回收
memcg_memory_event(memcg, MEMCG_LOW);
}
success = try_to_shrink_lruvec(lruvec, sc); // 关键回收,尝试缩短lru列表,也就是回收页面
shrink_slab(sc->gfp_mask, pgdat->node_id, memcg, sc->priority); // 回收slab内存,但不是必须步骤
......
return success ? MEMCG_LRU_YOUNG : 0;
}
接下来则通过try_to_shrink_lruvec->evict_folios->shrink_folio_list执行连续folios页面的回收。
4.1.2-压缩回收
Linux 内核内存子系统中用于在内存分配过程中尝试内存压缩(compaction)的函数。当内存碎片过多,导致连续内存页分配困难时,内存压缩可以将碎片合并,从而提高连续内存页分配的成功率。
static struct page *
__alloc_pages_direct_compact(gfp_t gfp_mask, unsigned int order,
unsigned int alloc_flags, const struct alloc_context *ac,
enum compact_priority prio, enum compact_result *compact_result)
{
......
*compact_result = try_to_compact_pages(gfp_mask, order, alloc_flags, ac,
prio, &page); // 执行压缩并获取page的逻辑
......
if (*compact_result == COMPACT_SKIPPED) // 如果无法执行压缩逻辑,直接退出
return NULL;
......
// 重新执行正常page准备逻辑
/* Prep a captured page if available */
if (page)
prep_new_page(page, order, gfp_mask, alloc_flags);
/* Try get a page from the freelist if available */
if (!page)
page = get_page_from_freelist(gfp_mask, order, alloc_flags, ac);
if (page) {
struct zone *zone = page_zone(page);
zone->compact_blockskip_flush = false;
compaction_defer_reset(zone, order, true);
count_vm_event(COMPACTSUCCESS);
return page;
}
......
return NULL;
}
在try_to_compact_pages中会遍历各个zone执行压缩逻辑compact_zone_order,而其中主要的调用逻辑则是compact_zone
其中关键流程如下:
- 调用
isolate_migratepages函数尝试隔离可迁移的页面。根据返回值进行相应的处理,如中止压缩、更新缓存的 PFN 等。 - 调用
migrate_pages函数迁移已隔离的页面。如果迁移失败,将页面放回到原始的 LRU 列表中。 - 如果捕获了一个页面(
capc->page),则将压缩结果设置为COMPACT_SUCCESS并跳出循环。 - 检查是否需要刷新已释放的页面,以便它们可以合并。如果需要,调用
lru_add_drain_cpu_zone函数进行刷新
static enum compact_result
compact_zone(struct compact_control *cc, struct capture_control *capc)
{
......
/*
* 设置迁移扫描器(migrate_pfn)和空闲扫描器(free_pfn)的起始位置。
* 这两个扫描器在内存压缩过程中分别负责查找可迁移的页面和空闲页面
*/
cc->fast_start_pfn = 0;
if (cc->whole_zone) {
cc->migrate_pfn = start_pfn;
cc->free_pfn = pageblock_start_pfn(end_pfn - 1);
} else {
cc->migrate_pfn = cc->zone->compact_cached_migrate_pfn[sync];
cc->free_pfn = cc->zone->compact_cached_free_pfn;
if (cc->free_pfn < start_pfn || cc->free_pfn >= end_pfn) {
cc->free_pfn = pageblock_start_pfn(end_pfn - 1);
cc->zone->compact_cached_free_pfn = cc->free_pfn;
}
if (cc->migrate_pfn < start_pfn || cc->migrate_pfn >= end_pfn) {
cc->migrate_pfn = start_pfn;
cc->zone->compact_cached_migrate_pfn[0] = cc->migrate_pfn;
cc->zone->compact_cached_migrate_pfn[1] = cc->migrate_pfn;
}
if (cc->migrate_pfn <= cc->zone->compact_init_migrate_pfn)
cc->whole_zone = true;
}
last_migrated_pfn = 0;
......
while ((ret = compact_finished(cc)) == COMPACT_CONTINUE) { // 循环执行压缩逻辑
int err;
unsigned long iteration_start_pfn = cc->migrate_pfn;
cc->finish_pageblock = false;
if (pageblock_start_pfn(last_migrated_pfn) ==
pageblock_start_pfn(iteration_start_pfn)) { // 开始压缩的页帧
cc->finish_pageblock = true;
}
rescan:
switch (isolate_migratepages(cc)) { // 隔离需要压缩、迁移的页面
case ISOLATE_ABORT:
ret = COMPACT_CONTENDED;
putback_movable_pages(&cc->migratepages);
cc->nr_migratepages = 0;
goto out;
case ISOLATE_NONE: // 找不到隔离页面了,就正常退出循环
if (update_cached) {
cc->zone->compact_cached_migrate_pfn[1] =
cc->zone->compact_cached_migrate_pfn[0];
}
/*
* We haven't isolated and migrated anything, but
* there might still be unflushed migrations from
* previous cc->order aligned block.
*/
goto check_drain;
case ISOLATE_SUCCESS:
update_cached = false;
last_migrated_pfn = max(cc->zone->zone_start_pfn,
pageblock_start_pfn(cc->migrate_pfn - 1));
}
err = migrate_pages(&cc->migratepages, compaction_alloc,
compaction_free, (unsigned long)cc, cc->mode,
MR_COMPACTION, &nr_succeeded); // 调用函数迁移已隔离的页面
trace_mm_compaction_migratepages(cc, nr_succeeded);
......
goto rescan;
}
}
/* Stop if a page has been captured */
if (capc && capc->page) { // 获取到了压缩页后,则退出循环
ret = COMPACT_SUCCESS;
break;
}
check_drain:
......
}
out:
......
return ret;
}
4.1.3-OOM
主动OOM回收通过执行__alloc_pages_may_oom的out_of_memorykill进程来获取内存。
/**
* out_of_memory - kill the "best" process when we run out of memory
* @oc: pointer to struct oom_control
*
* If we run out of memory, we have the choice between either
* killing a random task (bad), letting the system crash (worse)
* OR try to be smart about which process to kill. Note that we
* don't have to be perfect here, we just have to be good.
*/
bool out_of_memory(struct oom_control *oc)
{
unsigned long freed = 0;
if (oom_killer_disabled) // 如果禁用了OOM释放内存,就直接退出
return false;
if (!is_memcg_oom(oc)) {
blocking_notifier_call_chain(&oom_notify_list, 0, &freed);
if (freed > 0 && !is_sysrq_oom(oc))
/* Got some memory back in the last second. */
return true;
}
/*
* 如果有进程已经在排队kill了,就不需要执行后续逻辑
*/
if (task_will_free_mem(current)) {
mark_oom_victim(current);
queue_oom_reaper(current);
return true;
}
/*
* The OOM killer does not compensate for IO-less reclaim.
* But mem_cgroup_oom() has to invoke the OOM killer even
* if it is a GFP_NOFS allocation.
*/
if (!(oc->gfp_mask & __GFP_FS) && !is_memcg_oom(oc))
return true;
/*
* Check if there were limitations on the allocation (only relevant for
* NUMA and memcg) that may require different handling.
*/
oc->constraint = constrained_alloc(oc);
if (oc->constraint != CONSTRAINT_MEMORY_POLICY)
oc->nodemask = NULL;
check_panic_on_oom(oc);
if (!is_memcg_oom(oc) && sysctl_oom_kill_allocating_task &&
current->mm && !oom_unkillable_task(current) &&
oom_cpuset_eligible(current, oc) &&
current->signal->oom_score_adj != OOM_SCORE_ADJ_MIN) { // 不是由memcg引发的 OOM
get_task_struct(current); // 这直接kill当前分配内存的进程,也就是current
oc->chosen = current;
oom_kill_process(oc, "Out of memory (oom_kill_allocating_task)");// 通过sig kill进程
return true;
}
select_bad_process(oc); // 选择一个合适的进程进行kill
/* oom失败的处理逻辑 */
if (!oc->chosen) {
dump_header(oc);
pr_warn("Out of memory and no killable processes...\n");
/*
* If we got here due to an actual allocation at the
* system level, we cannot survive this and will enter
* an endless loop in the allocator. Bail out now.
*/
if (!is_sysrq_oom(oc) && !is_memcg_oom(oc))
panic("System is deadlocked on memory\n");
}
if (oc->chosen && oc->chosen != (void *)-1UL)
oom_kill_process(oc, !is_memcg_oom(oc) ? "Out of memory" :
"Memory cgroup out of memory"); // 通过sig kill进程
return !!oc->chosen;
}
内核通过select_bad_process选择一个合适进程进行kill,逻辑比较简单,就是遍历当前mem cgroup中或者其他全部进程中符合oom_evaluate_task进程。
/*
* Simple selection loop. We choose the process with the highest number of
* 'points'. In case scan was aborted, oc->chosen is set to -1.
*/
static void select_bad_process(struct oom_control *oc)
{
oc->chosen_points = LONG_MIN;
if (is_memcg_oom(oc))
mem_cgroup_scan_tasks(oc->memcg, oom_evaluate_task, oc); //
else {
struct task_struct *p;
rcu_read_lock();
for_each_process(p)
if (oom_evaluate_task(p, oc))
break;
rcu_read_unlock();
}
}
而oom_evaluate_task的标准是
static int oom_evaluate_task(struct task_struct *task, void *arg)
{
struct oom_control *oc = arg;
long points;
if (oom_unkillable_task(task)) // 非内核进程
goto next;
/* p may not have freeable memory in nodemask */
if (!is_memcg_oom(oc) && !oom_cpuset_eligible(task, oc)) // 没有申请内存的进程也不需要kill
goto next;
/*
* This task already has access to memory reserves and is being killed.
* Don't allow any other task to have access to the reserves unless
* the task has MMF_OOM_SKIP because chances that it would release
* any memory is quite low.
*/
if (!is_sysrq_oom(oc) && tsk_is_oom_victim(task)) {
if (test_bit(MMF_OOM_SKIP, &task->signal->oom_mm->flags))
goto next;
goto abort;
}
/*
* If task is allocating a lot of memory and has been marked to be
* killed first if it triggers an oom, then select it.
*/
if (oom_task_origin(task)) {
points = LONG_MAX; // 进程正在分配大量内存且已被标记为在触发 OOM 时优先杀死,那么选择它作为 OOM 受害者。
goto select;
}
points = oom_badness(task, oc->totalpages);
if (points == LONG_MIN || points < oc->chosen_points) // 分数低的则跳过
goto next;
select:
if (oc->chosen)
put_task_struct(oc->chosen);
get_task_struct(task);
oc->chosen = task;
oc->chosen_points = points;
next:
return 0;
abort:
......
return 1;
}
而在Linux中,OOM 分值的计算是通过oom_badness函数来完成的。以下是计算过程:
- 首先获取进程的内存使用量(resident set size,RSS),包括进程的用户态内存使用量和共享内存使用量。
- 计算进程的运行时长,即从进程启动到现在的时间。运行时长越长,进程的 OOM 分值越低,因为长时间运行的进程通常更重要。
- 根据进程的内存使用量和运行时长计算基本的 OOM 分值。这通常是将内存使用量除以运行时长,然后进行一定的比例缩放。
- 将进程的调整分数(oom_score_adj)应用到基本的 OOM 分值上。调整分数的范围是 -1000(OOM_SCORE_ADJ_MIN)到 1000(OOM_SCORE_ADJ_MAX)。负值表示进程更不容易被 OOM killer 杀死,正值表示进程更容易被杀死。调整分数可以通过
/proc/<pid>/oom_score_adj文件进行设置。
4.2-kswapd
kswapd是一个用来周期性扫描内存进行回收的功能。实际上看kswapd是一个模块
static int __init kswapd_init(void)
{
int nid;
swap_setup();
for_each_node_state(nid, N_MEMORY)
kswapd_run(nid);
return 0;
}
module_init(kswapd_init)
这个模块是在每一个numa上创建一个kswapd的线程
/*
* This kswapd start function will be called by init and node-hot-add.
*/
void __meminit kswapd_run(int nid)
{
pg_data_t *pgdat = NODE_DATA(nid);
pgdat_kswapd_lock(pgdat);
if (!pgdat->kswapd) {
pgdat->kswapd = kthread_run(kswapd, pgdat, "kswapd%d", nid);
if (IS_ERR(pgdat->kswapd)) {
/* failure at boot is fatal */
pr_err("Failed to start kswapd on node %d,ret=%ld\n",
nid, PTR_ERR(pgdat->kswapd));
BUG_ON(system_state < SYSTEM_RUNNING);
pgdat->kswapd = NULL;
}
}
pgdat_kswapd_unlock(pgdat);
}
kswapd线程的主逻辑是一个死循环的,通过
static int kswapd(void *p)
{
unsigned int alloc_order, reclaim_order;
unsigned int highest_zoneidx = MAX_NR_ZONES - 1;
pg_data_t *pgdat = (pg_data_t *)p;
struct task_struct *tsk = current;
const struct cpumask *cpumask = cpumask_of_node(pgdat->node_id);
......
for ( ; ; ) {
bool ret;
alloc_order = reclaim_order = READ_ONCE(pgdat->kswapd_order);
highest_zoneidx = kswapd_highest_zoneidx(pgdat,
highest_zoneidx);
kswapd_try_sleep:
kswapd_try_to_sleep(pgdat, alloc_order, reclaim_order,
highest_zoneidx); // 在睡眠之前,kswapd会检查是否有足够的空闲内存,如果有足够的空闲内存,kswapd将继续睡眠。
/* Read the new order and highest_zoneidx */
alloc_order = READ_ONCE(pgdat->kswapd_order);
highest_zoneidx = kswapd_highest_zoneidx(pgdat,
highest_zoneidx);
WRITE_ONCE(pgdat->kswapd_order, 0);
WRITE_ONCE(pgdat->kswapd_highest_zoneidx, MAX_NR_ZONES);
ret = try_to_freeze(); // 检查是否需要冻结当前线程
if (kthread_should_stop()) // 通过kthread_stop终止进程
break;
/*
* We can speed up thawing tasks if we don't call balance_pgdat
* after returning from the refrigerator
*/
if (ret)
continue;
/*
* Reclaim begins at the requested order but if a high-order
* reclaim fails then kswapd falls back to reclaiming for
* order-0. If that happens, kswapd will consider sleeping
* for the order it finished reclaiming at (reclaim_order)
* but kcompactd is woken to compact for the original
* request (alloc_order).
*/
trace_mm_vmscan_kswapd_wake(pgdat->node_id, highest_zoneidx,
alloc_order);
reclaim_order = balance_pgdat(pgdat, alloc_order,
highest_zoneidx); // 根据给定的alloc_order和highest_zoneidx回收内存
if (reclaim_order < alloc_order)
goto kswapd_try_sleep;
}
tsk->flags &= ~(PF_MEMALLOC | PF_KSWAPD);
return 0;
}
实际上kswapd最终也会通过调用shrink_node来执行内存的具体回收,相比之前分析的在分配内存的区别是:
这段代码主要用于在kswapd线程执行内存回收时进行一些特殊处理,以解决脏页写回速度较慢的问题。这些处理包括设置PGDAT_WRITEBACK和PGDAT_DIRTY标志,以及在某些情况下强制kswapd暂停等待页面写回。
if (current_is_kswapd()) {
/*
* If reclaim is isolating dirty pages under writeback,
* it implies that the long-lived page allocation rate
* is exceeding the page laundering rate. Either the
* global limits are not being effective at throttling
* processes due to the page distribution throughout
* zones or there is heavy usage of a slow backing
* device. The only option is to throttle from reclaim
* context which is not ideal as there is no guarantee
* the dirtying process is throttled in the same way
* balance_dirty_pages() manages.
*
* Once a node is flagged PGDAT_WRITEBACK, kswapd will
* count the number of pages under pages flagged for
* immediate reclaim and stall if any are encountered
* in the nr_immediate check below.
*/
if (sc->nr.writeback && sc->nr.writeback == sc->nr.taken)
set_bit(PGDAT_WRITEBACK, &pgdat->flags);
/* Allow kswapd to start writing pages during reclaim.*/
if (sc->nr.unqueued_dirty == sc->nr.file_taken)
set_bit(PGDAT_DIRTY, &pgdat->flags);
/*
* If kswapd scans pages marked for immediate
* reclaim and under writeback (nr_immediate), it
* implies that pages are cycling through the LRU
* faster than they are written so forcibly stall
* until some pages complete writeback.
*/
if (sc->nr.immediate)
reclaim_throttle(pgdat, VMSCAN_THROTTLE_WRITEBACK);
}
另外,pgdat->kswapd_order的值是根据内存分配器的需求动态设置的。当内存分配器尝试分配较大的连续内存块(即较高的order值)时,如果分配失败,内存分配器会唤醒kswapd线程并更新pgdat->kswapd_order的值。
4.2.2-kswapd唤醒
在刚刚分析的函数中kswapd_try_to_sleep,kswapd将自己放置在队列中等待唤醒,因此唤醒的方式就是调度这个队列。
static void kswapd_try_to_sleep(pg_data_t *pgdat, int alloc_order, int reclaim_order,
unsigned int highest_zoneidx)
{
......
prepare_to_wait(&pgdat->kswapd_wait, &wait, TASK_INTERRUPTIBLE);
......
}
kswapd可以通过设置wake_up_interruptible(pgdat->kswapd_wait)直接唤醒kswapd线程。
- 在
try_to_free_pages执行主动回收的时候,会调用throttle_direct_reclaim->allow_direct_reclaim来唤醒kswapd线程
kswapd也可以通过wakeup_kswapd来唤醒。
-
在
__alloc_pages_slowpath通过慢速路径分配内存的时候调用,这种情况下是没有在伙伴系统中找到可以用的page,所以在分配的同时异步执行回收线程。 -
另外再调用
rmqueue时,系统在分配完成后,也会通过检查水位线,来判断是否需要调用wakeup_kswapd执行内存回收。
4.3-slab收割
在slab中(注意是专属slab.c而不是slab内存),存在一个slab收割的主动进程,但是值得注意的是,这个功能在slub.c中并不存在,并且这个线程也会造成cpu周期性的占用(Documentation/admin-guide/kernel-per-CPU-kthreads.rst)
3. Do any of the following needed to avoid jitter that your
application cannot tolerate:
a. Build your kernel with CONFIG_SLUB=y rather than
CONFIG_SLAB=y, thus avoiding the slab allocator's periodic
use of each CPU's workqueues to run its cache_reap()
function.
初始化绑定的进程就是如下,会定时的运行cache_reap,也就是slab回收工作,
static void start_cpu_timer(int cpu)
{
struct delayed_work *reap_work = &per_cpu(slab_reap_work, cpu);
if (reap_work->work.func == NULL) {
init_reap_node(cpu);
INIT_DEFERRABLE_WORK(reap_work, cache_reap);
schedule_delayed_work_on(cpu, reap_work,
__round_jiffies_relative(HZ, cpu));
}
}
主要逻辑如下
static void cache_reap(struct work_struct *w)
{
......
list_for_each_entry(searchp, &slab_caches, list) { // 遍历所有的slab
check_irq_on();
/*
* We only take the node lock if absolutely necessary and we
* have established with reasonable certainty that
* we can do some work if the lock was obtained.
*/
n = get_node(searchp, node);// 获取slab对应的node
reap_alien(searchp, n); // 回收n对应numa上的本地slab
drain_array(searchp, n, cpu_cache_get(searchp), node); // 回收per cpu cache上的slab
......
if (n->free_touched) // 二次机会,如果最近用过,就不回收
n->free_touched = 0;
else {
int freed;
freed = drain_freelist(searchp, n, (n->free_limit +
5 * searchp->num - 1) / (5 * searchp->num));
STATS_ADD_REAPED(searchp, freed); // 每次只回收一定比例的free slab
}
next:
cond_resched();
}
check_irq_on();
mutex_unlock(&slab_mutex);
next_reap_node();
out:
/* Set up the next iteration */
schedule_delayed_work_on(smp_processor_id(), work,
round_jiffies_relative(REAPTIMEOUT_AC));
}
而在回收的时候会判断touched是不是为0,这代表slab最近有没有被访问,如果访问的话则不会被回收,而是将touched置为0,等待下一次再判断,这也是常说的二次机会。
并且drain_freelist()函数的回收阈值是(n->free_limit + 5 * searchp->num - 1) / (5 * searchp->num)。这个公式可以确保每次回收操作只释放一定比例的内存对象。



