内存管理3_slab_slub

1、SLAB 内存分配器
SLAB 内存分配器是 Linux 内核中用于管理内核对象的一种机制,它通过预分配和重用对象来优化性能。
The Slab Allocator: An Object-Caching Kernel Memory Allocator
1.1-基本原理
操作系统中内存碎片是一个常见的需要解决严重问题,我们上一片文章已经分析了Linux内核中的一种解法:伙伴系统,内核通过合并、拆分分配好的20~10个连续内存页框的块来避免内存碎片化的问题,但是伙伴系统仍存在下列问题:
-
粒度过大
通过伙伴系统的原理可以发现,伙伴系统最小的粒度的是
order为0的时候,也就是一个页的内存大小。但是内核中还是有大量小内存(<1kb级别)的申请,如果这些时候依然分配一整个页获取,就会造成大量的内存洞也叫做内碎片问题,浪费大量空间。 -
性能开销大:
伙伴系统在申请和释放的过程中会存在比较多的合并和拆分的逻辑,在频繁申请和释放的过程中会存在比较大的性能开销。
因此内核中引入了一个新的概念,最初由Sun公司设计的slab内存分配器,其具有如下特点:
- 预分配对象集:SLAB 分配器通过创建一组预先分配的对象集(称为 "slabs")来减少为每个新对象单独分配和释放内存的开销。这些对象集可以叫做
cache。 - 对象重用:当一个对象被释放时,它不是被销毁,而是保留在 slab 中,以便下次快速重新使用。
- 减少开销:这种方法减少了内存分配的时间开销,特别是对于频繁创建和销毁的小对象。
SLAB分配器从伙伴系统中获取连续的页,并将这些页分割成几个slab块,在每个slab块中包含若个对象
1.2-源码分析
1.2.1-kmem_cache
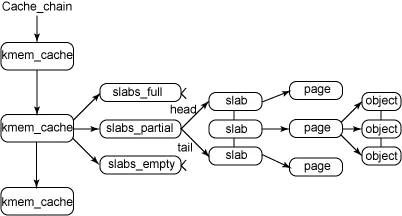
slab的核心结构体是kmem_cache,这里记录着一种slab成员
struct kmem_cache {
struct array_cache __percpu *cpu_cache; // slab对应的per cpu cache
/* 1) Cache tunables. Protected by slab_mutex */
unsigned int batchcount;
unsigned int limit;
unsigned int shared;
unsigned int size;
struct reciprocal_value reciprocal_buffer_size;
/* 2) touched by every alloc & free from the backend */
slab_flags_t flags; /* 标志位,用于标识缓存的属性 */
unsigned int num; /* 每个SLAB中对象的数量 */
/* 3) cache_grow/shrink */
unsigned int gfporder; // 一个slab中指定分配页框数
gfp_t allocflags; // 申请的页框flag
size_t colour; /* slab着色标记位,用于避免缓存行冲突*/
unsigned int colour_off; /* 着色偏移 */
unsigned int freelist_size;
/* constructor func */
void (*ctor)(void *obj); // 内存分配后的回调
/* 4) cache creation/removal */
const char *name; // slab类型名称
struct list_head list; // slab全局缓存链表头
int refcount; // 引用计数
int object_size; // slab类型对应的对象大小
int align; // 对齐大小
/* 5) statistics */
......
#ifdef CONFIG_HARDENED_USERCOPY
unsigned int useroffset; /* Usercopy region offset */
unsigned int usersize; /* Usercopy region size */
#endif
struct kmem_cache_node *node[MAX_NUMNODES]; // 每一个slab的缓存结构体,一个node对应一个
};
kmem_cache中成员的关系如下图所示
1.2.2-kmem_cache_node
struct kmem_cache_node {
#ifdef CONFIG_SLAB
raw_spinlock_t list_lock;
struct list_head slabs_partial; /* 部分分配的slab */
struct list_head slabs_full; /* 分配完的slab */
struct list_head slabs_free; /* 还没分配的slab */
unsigned long total_slabs; /* 表示所有slab列表的长度 */
unsigned long free_slabs; /* 表示空闲slab列表的长度 */
unsigned long free_objects;
unsigned int free_limit;
unsigned int colour_next; /* Per-node cache coloring */
struct array_cache *shared; /* shared per node */
struct alien_cache **alien; /* on other nodes */
unsigned long next_reap; /* updated without locking */
int free_touched; /* updated without locking */
#endif
};
kmem_cache_node是kmem链表中的具体成员
其中比较重要的数据结构就是slabs_partial、slabs_full、slabs_free,这三个列表分别指向了:
- 部分使用的slab块
- 全部使用的slab块
- 还没有使用的slab块
因此,最终形成的数据结构关系如下
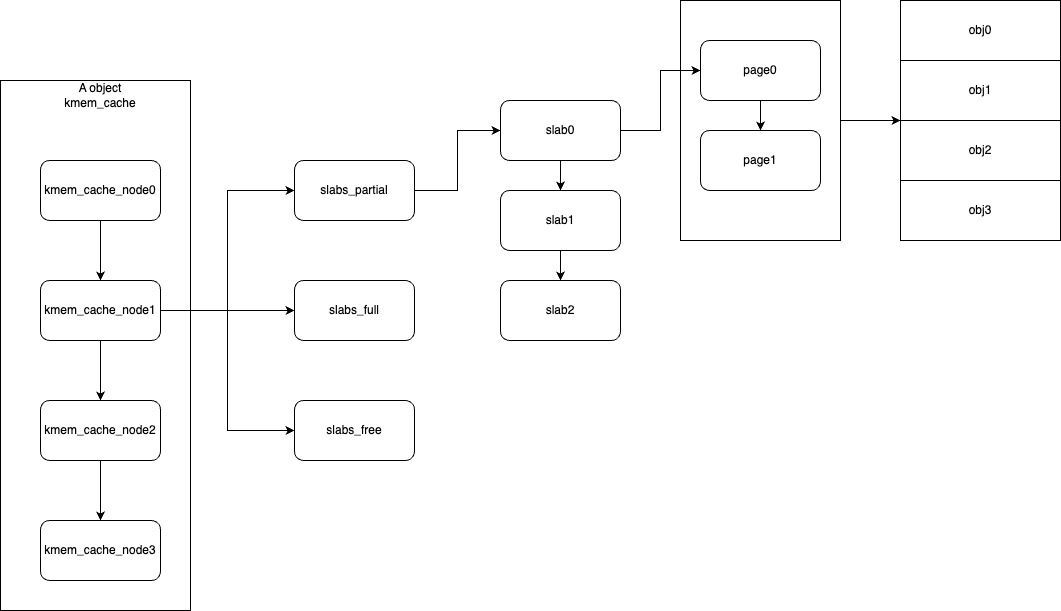
(通常只有两个node)
1.2.3 slab的操作函数
创建一种slab的api,这个允许了内核驱动直接调用创建一中新的obj slab缓存
struct kmem_cache *
kmem_cache_create(const char *name, unsigned int size, unsigned int align,
slab_flags_t flags, void (*ctor)(void *))
{
return kmem_cache_create_usercopy(name, size, align, flags, 0, 0,
ctor);
}
EXPORT_SYMBOL(kmem_cache_create);
这里只是初始化了slab的最上层数据结构kmem_cache,而没有具体分配页面。分配函数时kmem_cache_alloc
其中调用关系如下
kmem_cache_alloc->__kmem_cache_alloc_lru->slab_alloc->slab_alloc_node->__do_cache_alloc,此时如果是numa结构则会进一步在近端内存上调用____cache_alloc,而失败了再调用____cache_alloc_node尝试从指定的NUMA分配对象,而不支持numa的则直接是____cache_alloc。
而释放slab对象的函数是kmem_cache_free
void kmem_cache_free(struct kmem_cache *cachep, void *objp)
{
cachep = cache_from_obj(cachep, objp);
if (!cachep)
return;
trace_kmem_cache_free(_RET_IP_, objp, cachep);
__do_kmem_cache_free(cachep, objp, _RET_IP_);
}
EXPORT_SYMBOL(kmem_cache_free);
1.3-cpu cache
每一种slab都会有cpu cache的slab缓存
/*
* struct array_cache
*
* Purpose:
* - LIFO ordering, to hand out cache-warm objects from _alloc
* - reduce the number of linked list operations
* - reduce spinlock operations
*
* The limit is stored in the per-cpu structure to reduce the data cache
* footprint.
*
*/
struct array_cache {
unsigned int avail;
unsigned int limit;
unsigned int batchcount;
unsigned int touched;
void *entry[]; /*
* Must have this definition in here for the proper
* alignment of array_cache. Also simplifies accessing
* the entries.
*/
};
正如注释所示,使用cpu cache上slab的好处在于是减少锁竞争、使用cache上的热数据有助于性能、减少链表操作等好处。
每次free一个对象的时候,会把slab放到array_cache中的entry数组里,详细可以看后边free的分析。
当需要将一个对象归还到kmem_cache时,首先尝试将对象放回当前CPU的数组缓存。如果数组缓存已满,则将数组缓存中的对象归还到全局缓存。这个过程称为“刷新”(flush)。
以下是SLAB分配器在这两个过程中与数组缓存交互的关键函数:
-
填充(refill):
当从
kmem_cache中分配一个对象时,如果当前CPU的数组缓存为空,会调用cache_alloc_refill()函数。这个函数会从全局缓存中获取一组对象并填充到数组缓存中。然后,从数组缓存中分配一个对象返回。 -
刷新(flush):
当将一个对象归还到
kmem_cache时,如果当前CPU的数组缓存已满,会调用cache_flusharray()函数。这个函数会将数组缓存中的对象归还到全局缓存。
虽然,我们不能保证array_cache中的对象一定位于CPU高速缓存中,因为CPU高速缓存的大小有限,而且还需要存储其他数据。然而,由于SLAB分配器的设计,array_cache中的对象更有可能位于CPU高速缓存中,从而提高内存分配和释放的性能。但是由于array_cache是per_cpu变量,因此在执行这个这些数据变量的时候可以不需要加锁,从而确定性的提高了内存分配器的性能。
1.4-kmalloc
kmalloc被定义在include/linux/slab.h
static __always_inline __alloc_size(1) void *kmalloc(size_t size, gfp_t flags)
{
if (__builtin_constant_p(size) && size) {
unsigned int index;
if (size > KMALLOC_MAX_CACHE_SIZE)
return kmalloc_large(size, flags);
index = kmalloc_index(size);
return kmalloc_trace(
kmalloc_caches[kmalloc_type(flags, _RET_IP_)][index],
flags, size);
}
return __kmalloc(size, flags);
}
/* Maximum size for which we actually use a slab cache */
#define KMALLOC_MAX_CACHE_SIZE (1UL << KMALLOC_SHIFT_HIGH)
// x86中的定义是
#define KMALLOC_SHIFT_HIGH (PAGE_SHIFT + 1)
#define PAGE_SHIFT 12
__builtin_constant_p(size):这是一个GCC编译器内建函数,用于检查给定的参数size是否是一个编译时常量。如果size是一个编译时常量,函数返回真(非零值)的时候分配大size的cache时使用的是kmalloc_large,不然则调用kmalloc_trace。
-
kmalloc_large->__kmalloc_large_node->alloc_pages_node所以从这里可以看到,分配大size(>8KB)的内存时,则会直接分配新的也,而不是从slab中获取。
-
kmalloc_trace->__kmem_cache_alloc_node(s, gfpflags, NUMA_NO_NODE,size, _RET_IP_);->slab_alloc_node->__do_cache_alloc->____cache_alloc -
__kmalloc->__do_kmalloc_node->__kmem_cache_alloc_node(s, flags, node, size, caller);->slab_alloc_node->__do_cache_alloc->____cache_alloc
其中____cache_alloc
static inline void *____cache_alloc(struct kmem_cache *cachep, gfp_t flags)
{
.....
ac = cpu_cache_get(cachep); // 尝试从cpu cache里找一个地址
if (likely(ac->avail)) {
ac->touched = 1;
objp = ac->entry[--ac->avail];
STATS_INC_ALLOCHIT(cachep);
goto out;
}
STATS_INC_ALLOCMISS(cachep);
objp = cache_alloc_refill(cachep, flags); // 没有的话就从公共的slab里找
......
return objp;// 拿到的obj地址指针
}
1.5-kfree
在mm/slab_common.c
void kfree(const void *object)
{
struct folio *folio;
struct slab *slab;
struct kmem_cache *s;
trace_kfree(_RET_IP_, object);
if (unlikely(ZERO_OR_NULL_PTR(object)))
return;
folio = virt_to_folio(object);
if (unlikely(!folio_test_slab(folio))) {
free_large_kmalloc(folio, (void *)object);
return;
}
slab = folio_slab(folio);
s = slab->slab_cache;
__kmem_cache_free(s, (void *)object, _RET_IP_);
}
EXPORT_SYMBOL(kfree);
最终会调用到
void ___cache_free(struct kmem_cache *cachep, void *objp,
unsigned long caller)
{
......
// NUMA的是调用cache_free_alien将对象放回到对应numa上
if (nr_online_nodes > 1 && cache_free_alien(cachep, objp))
return;
if (ac->avail < ac->limit) {
STATS_INC_FREEHIT(cachep);
} else {
STATS_INC_FREEMISS(cachep);
cache_flusharray(cachep, ac); // 如果当前cpu cache中的slab超过限制,则从cpu数组中搬运回本地中。
}
......
__free_one(ac, objp); // 将对象放回当前CPU cache的缓存
}
可以看到__free_one会把objp放到用avail计数的entry之中
/* &alien->lock must be held by alien callers. */
static __always_inline void __free_one(struct array_cache *ac, void *objp)
{
/* Avoid trivial double-free. */
if (IS_ENABLED(CONFIG_SLAB_FREELIST_HARDENED) &&
WARN_ON_ONCE(ac->avail > 0 && ac->entry[ac->avail - 1] == objp))
return;
ac->entry[ac->avail++] = objp;
}
1.6-着色
在这里补充一下着色的概念:
- 当CPU需要处理内存中的数据时,它首先将这些数据从主内存加载到自己的高速缓存(Cache)中。
- 在slab分配器中,kmem_cache是用来管理一系列大小相同的对象的。每个kmem_cache中的slab由一系列连续的页框(pages)组成,而每个页框包含了多个对象。
- 由于所有slab都是由相同长度的页框组成,因此在不同slab中同一对象号的对象相对于页框的起始地址的偏移量是相同的。
- CPU缓存是分成多个缓存行(cache lines)的,每个缓存行可以加载一定量的数据。当两个对象(即使它们位于不同的slab中)具有相同的偏移量时,它们可能会被加载到同一个缓存行中(CPU加载具有相同偏移量的不同内存地址时,会基于偏移确定其映射到的缓存行)。这意味着,如果CPU交替操作这两个对象,它可能需要不断地从一个对象换到另一个对象,每次操作都可能导致缓存行的重新加载。
- 当CPU频繁地在两个缓存行之间交换数据时,会发生缓存抖动。这会显著降低缓存的效率,因为CPU不得不花费额外的时间来加载和重新加载数据,而不是直接从缓存中快速访问数据。
基于上述内容,SLAB中增加了一个着色偏移,使得不同slab块中的相同号对象偏移不同,这样保证cpu cache line可以同时保留他们,而不是因为位置重叠只能保留一个slab块的内容。
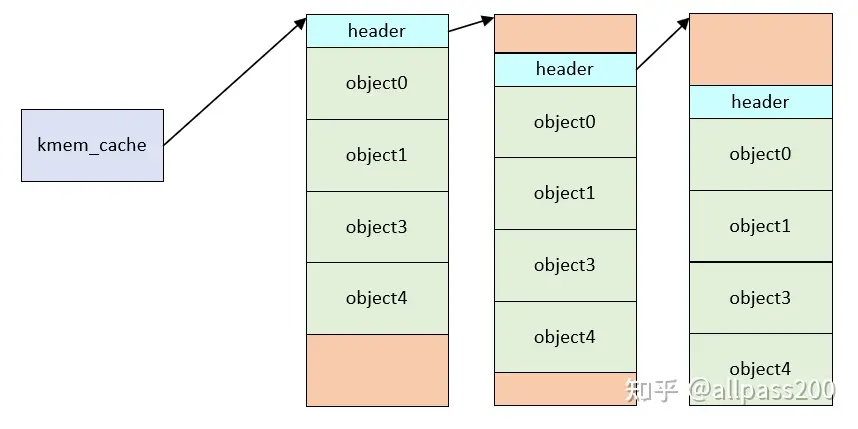
from Linux中的内存分配--slab(1)
2、SLUB 内存分配器
SLUB (Simplified Allocator) 是 Linux 内核中的一种内存分配器,旨在提高性能并简化 slab 分配器的复杂性。
2.1-设计目标与优化
- CPU缓存友好:SLUB 分配器旨在优化对象的布局以提高 CPU 缓存命中率。它通过将相关对象放置在相邻的内存位置来减少缓存未命中。
- 减少内存碎片:与传统的 slab 分配器相比,SLUB 试图通过更精细的对象管理减少内存碎片。
- 简化结构:SLUB 移除了 slab 分配器中的一些复杂的缓存机制,使代码更易于维护和理解。slab块中存在三种链表,也就是部分空闲、空闲、满三个,而在slub将他们精简成一个。
2.2-数据结构
在include/linux/slub_def.h中定义了slub自己的kmem_cache结构体。
struct kmem_cache {
#ifndef CONFIG_SLUB_TINY
struct kmem_cache_cpu __percpu *cpu_slab; // 依然是per cpu上的缓存变量,但是名字不再是ac了
#endif
/* Used for retrieving partial slabs, etc. */
slab_flags_t flags;
unsigned long min_partial;
unsigned int size; /* The size of an object including metadata */
unsigned int object_size;/* The size of an object without metadata */
struct reciprocal_value reciprocal_size;
unsigned int offset; /* Free pointer offset */
#ifdef CONFIG_SLUB_CPU_PARTIAL
/* Number of per cpu partial objects to keep around */
unsigned int cpu_partial;
/* Number of per cpu partial slabs to keep around */
unsigned int cpu_partial_slabs;
#endif
struct kmem_cache_order_objects oo;
/* Allocation and freeing of slabs */
struct kmem_cache_order_objects min;
gfp_t allocflags; /* gfp flags to use on each alloc */
int refcount; /* Refcount for slab cache destroy */
void (*ctor)(void *);
unsigned int inuse; /* Offset to metadata */
unsigned int align; /* Alignment */
unsigned int red_left_pad; /* Left redzone padding size */
const char *name; /* Name (only for display!) */
struct list_head list; /* kmem_cache自己管理的链表 */
......
#ifdef CONFIG_NUMA
/*
* 用于NUMA架构,该值越小,越倾向于在本结点分配对象
*/
unsigned int remote_node_defrag_ratio;
#endif
......
struct kmem_cache_node *node[MAX_NUMNODES]; // slab对应的具体地址数组,每个node上一个
};
而在kmem_cache_node部分可以比较明显的体现出差别,这里只保留的一个partial链表用来存放slab具体对象,并且删除了共享的cpu与node共享cache,是 struct array_cache 与struct alien_cache 。
struct kmem_cache_node {
#ifdef CONFIG_SLAB
raw_spinlock_t list_lock;
struct list_head slabs_partial; /* partial list first, better asm code */
struct list_head slabs_full;
struct list_head slabs_free;
unsigned long total_slabs; /* length of all slab lists */
unsigned long free_slabs; /* length of free slab list only */
unsigned long free_objects;
unsigned int free_limit;
unsigned int colour_next; /* Per-node cache coloring */
struct array_cache *shared; /* shared per node */
struct alien_cache **alien; /* on other nodes */
unsigned long next_reap; /* updated without locking */
int free_touched; /* updated without locking */
#endif
#ifdef CONFIG_SLUB
spinlock_t list_lock;
unsigned long nr_partial;
struct list_head partial;
#ifdef CONFIG_SLUB_DEBUG
atomic_long_t nr_slabs;
atomic_long_t total_objects;
struct list_head full;
#endif
#endif
};
而对于slub中的cpu cache部分在slub中也简化了许多,SLAB分配器的每CPU结构中保存的是空闲对象链表,而SLUB分配器的每CPU结构中保存的是一个slab缓冲区。其数据结构kmem_cache_cpu具体如下
struct kmem_cache_cpu {
union {
struct {
void **freelist; /* 指向下一个obj对象 */
unsigned long tid; /* 用于保证cmpxchg_double计算发生在正确的CPU上 */
};
freelist_aba_t freelist_tid;
};
struct slab *slab; /* 这个结构体本身就是一个slab对象 */
#ifdef CONFIG_SLUB_CPU_PARTIAL
struct slab *partial; /* Partially allocated frozen slabs */
#endif
local_lock_t lock; /* Protects the fields above */
#ifdef CONFIG_SLUB_STATS
unsigned stat[NR_SLUB_STAT_ITEMS];
#endif
};
所以最终形成结构如下
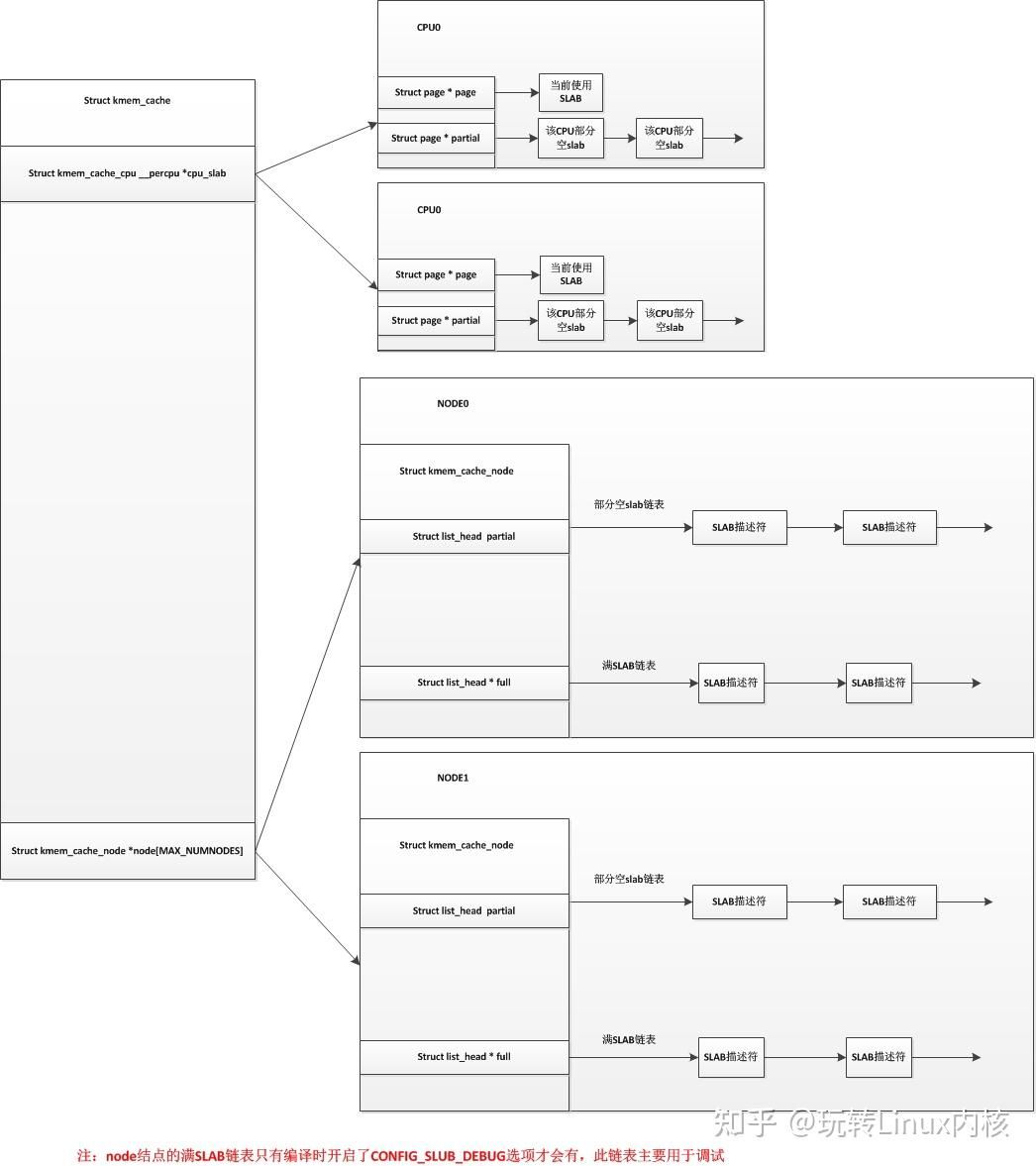
from 玩转Linux内核
2.3-分配与释放流程
为了保持代码一致,slub部分的关键api和slab保持的一致原型。类似于slub中的kmem_cache_alloc与kmem_cache_free都是新定义的api,只不过名称和参数重合。
并且slab调用的__kmem_cache_create在slub中也有重新定义
2.3.1 slub初始化
slub的创建由mm/slab_common.c中的create_cache调用。
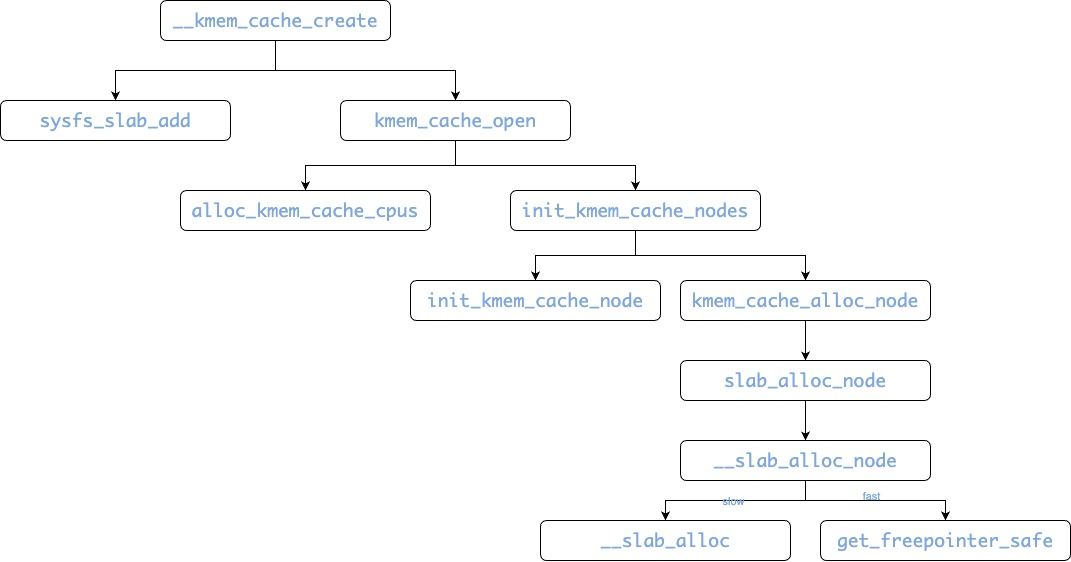
其中最终会通过调用new_slab来从伙伴系统中实际分配一系列page到这个slab之中
new_slab->allocate_slab->alloc_slab_page
static inline struct slab *alloc_slab_page(gfp_t flags, int node,
struct kmem_cache_order_objects oo)
{
struct folio *folio; // 存储从伙伴系统分配的连续物理页
struct slab *slab;
unsigned int order = oo_order(oo);
// 根据numa的情况从不同node上获取page
if (node == NUMA_NO_NODE)
folio = (struct folio *)alloc_pages(flags, order);
else
folio = (struct folio *)__alloc_pages_node(node, flags, order);
if (!folio)
return NULL;
slab = folio_slab(folio); // 获取与分配的页面关联
__folio_set_slab(folio); // 将folio结构与slab关联
/* Make the flag visible before any changes to folio->mapping */
smp_wmb();
if (folio_is_pfmemalloc(folio))
slab_set_pfmemalloc(slab);
return slab;
}
2.3.2 slub释放
slub通过slab_free释放一个slub对象。并最终调用到do_slab_free来释放对象
static __always_inline void do_slab_free(struct kmem_cache *s,
struct slab *slab, void *head, void *tail,
int cnt, unsigned long addr)
{
void *tail_obj = tail ? : head;
struct kmem_cache_cpu *c;
unsigned long tid;
void **freelist;
redo:
/*
* Determine the currently cpus per cpu slab.
* The cpu may change afterward. However that does not matter since
* data is retrieved via this pointer. If we are on the same cpu
* during the cmpxchg then the free will succeed.
*/
c = raw_cpu_ptr(s->cpu_slab);
tid = READ_ONCE(c->tid);
......
if (unlikely(slab != c->slab)) {
__slab_free(s, slab, head, tail_obj, cnt, addr); // 如果per cpu上的不一致,则退回给全局slab
return;
}
if (USE_LOCKLESS_FAST_PATH()) { // 快速路径
freelist = READ_ONCE(c->freelist);
set_freepointer(s, tail_obj, freelist); // 主要区别是使用了无锁操作,把obj还回给freelist
......
}
} else {
/* Update the free list under the local lock */
......
}
stat(s, FREE_FASTPATH);
}
其中,只有没使用实时抢占的系统CONFIG_PREEMPT_RT,都可以使用无锁的快速路径,毕竟这里是per cpu的操作,不存在并发操作。
2.4-性能考量
- 对小型和频繁分配的处理:SLUB 分配器在处理频繁的小型对象分配时表现出色,尤其是在多处理器系统中,由于其对 CPU 缓存的优化。
- 缩放性和并发性:SLUB 显示出良好的缩放性能和并发处理能力,特别是在多核环境下。
2.5-kmalloc
当使能了slub之后,内存分配器则会从slub中分配内存,前边几层调用没有变化,区别主要在slab_alloc_node开始,kmalloc会分别使用slub.c与slab.c的内容。
如前边分析,slab_alloc_node在没有slab的情况下会优先从本地node公共的partial list中找一个可用的slab,如果失败了最终调用new_slab进行伙伴系统内存page的分配。
static void *___slab_alloc(struct kmem_cache *s, gfp_t gfpflags, int node,
unsigned long addr, struct kmem_cache_cpu *c, unsigned int orig_size)
{
......
new_objects:
pc.flags = gfpflags;
pc.slab = &slab;
pc.orig_size = orig_size;
freelist = get_partial(s, node, &pc); // 从公共partial list找一个可用的slab
if (freelist)
goto check_new_slab;
slub_put_cpu_ptr(s->cpu_slab);
slab = new_slab(s, gfpflags, node); // 如果没找到则新分配一个
c = slub_get_cpu_ptr(s->cpu_slab);
......
}
而快速路径则会调用get_freepointer_safe直接从slab中的list直接通过地址偏移的方式获取一个slab obj内存。
static __always_inline void *__slab_alloc_node(struct kmem_cache *s,
gfp_t gfpflags, int node, unsigned long addr, size_t orig_size)
{
......
slab = c->slab;
if (!USE_LOCKLESS_FAST_PATH() ||
unlikely(!object || !slab || !node_match(slab, node))) {
object = __slab_alloc(s, gfpflags, node, addr, c, orig_size);
} else {
void *next_object = get_freepointer_safe(s, object);
......
}
......
}
3、SLOB 内存分配器
而slob分配器其实是更简化的slub分配器,在内核起开CONFIG_SLUB_TINY宏后,则会使能slob。
- 简化内存管理: SLOB 分配器是如何提供一种更简单的内存管理方式,没有CPU cache结构,分配和释放上更简单。
- 适用场景:嵌入式系统(RAM < 16MB),没有NUMA概念。
config SLUB_TINY
bool "Configure SLUB for minimal memory footprint"
depends on SLUB && EXPERT
select SLAB_MERGE_DEFAULT
help
Configures the SLUB allocator in a way to achieve minimal memory
footprint, sacrificing scalability, debugging and other features.
This is intended only for the smallest system that had used the
SLOB allocator and is not recommended for systems with more than
16MB RAM.
If unsure, say N.
在slob中是没有cpu cache slab的定义的
static inline int alloc_kmem_cache_cpus(struct kmem_cache *s)
{
return 1;
}
因此,释放和创建函数都十分的简化,操作都是直接将obj放回到对应的共享slab list即可
static void *__slab_alloc_node(struct kmem_cache *s,
gfp_t gfpflags, int node, unsigned long addr, size_t orig_size)
{
struct partial_context pc;
struct slab *slab;
void *object;
pc.flags = gfpflags;
pc.slab = &slab;
pc.orig_size = orig_size;
object = get_partial(s, node, &pc);
if (object)
return object;
slab = new_slab(s, gfpflags, node);
if (unlikely(!slab)) {
slab_out_of_memory(s, gfpflags, node);
return NULL;
}
object = alloc_single_from_new_slab(s, slab, orig_size);
return object;
}
static void do_slab_free(struct kmem_cache *s,
struct slab *slab, void *head, void *tail,
int cnt, unsigned long addr)
{
void *tail_obj = tail ? : head;
__slab_free(s, slab, head, tail_obj, cnt, addr);
}



