linux进程管理-2进程创建

0、前言
主要分析进程创建fork,线程、进程关系、copy_on_write。
1、复制进程
fork是通过复制父进程的方式来创建一个新的进程,内核中相关键函数和流程主要是被定义在了kernel/fork.c之中,通过fork.c里我们可以看到,有几个常用的sys_call:
forkvfork
#ifdef __ARCH_WANT_SYS_FORK
SYSCALL_DEFINE0(fork)
{
#ifdef CONFIG_MMU
struct kernel_clone_args args = {
.exit_signal = SIGCHLD,
};
return kernel_clone(&args);
#else
/* can not support in nommu mode */
return -EINVAL;
#endif
}
#endif
#ifdef __ARCH_WANT_SYS_VFORK
SYSCALL_DEFINE0(vfork)
{
struct kernel_clone_args args = {
.flags = CLONE_VFORK | CLONE_VM,
.exit_signal = SIGCHLD,
};
return kernel_clone(&args);
}
#endif
接下里的内容我们就会分析一下这些调用流程。
1.1-fork
fork的作用是:完全复制父进程,fork 创建的子进程是父进程的一个完整副本,包括父进程的数据段、堆和栈的副本。
通过fork的定义可以看到,在调用kernel_clone之前,填充了kernel_clone_args结构体。
struct kernel_clone_args args = {
.exit_signal = SIGCHLD,
};
这里的exit_signal表示当子进程退出时,用来通知父进程的信号,比如 SIGCHLD。
而所谓的父进程也就是创建他的进程,当父进程接收到了这个信号后,就会对其进行后续的相关处理,这里具体的收尸操作我们后续一起分析。
另外为了节省操作,fork在创建进程的时候,暂时不会在创建进程的时候就为子进程准备好具体的内存空间,只在具体修改时才会分配实际的内存空间,这就是copy-on-write也就是写时复制的操作。
1.2-vfork
而在vfork中,传递的参数有点区别。
struct kernel_clone_args args = {
.flags = CLONE_VFORK | CLONE_VM,
.exit_signal = SIGCHLD,
};
可以看到,这里在传递flag中增加了两个标记,而其作用主要是在后续流程中区分vfork操作,vfork创建的子进程与父进程共享相同的内存空间。
但是貌似vfork的使用比较少,尤其是在fork存在copy-on-write的背景下。
1.3-kernel_clone
不论是fork还是vfork,最终都会调用到kernel_clone。
kernel_clone在v5.10里被引入到内核之中,在旧的版本中是do_fork。
commit cad6967ac10843a70842cd39c7b53412901dd21f
Author: Christian Brauner <brauner@kernel.org>
Date: Wed Aug 19 12:46:45 2020 +0200
fork: introduce kernel_clone()
接下来我们分析一下kerne_clone的具体内容,核心的操作是调用copy_process复制进程。
pid_t kernel_clone(struct kernel_clone_args *args)
{
......
p = copy_process(NULL, trace, NUMA_NO_NODE, args); // 主要进行进程复制
add_latent_entropy(); // 创建新进程时增加一些随机性,从而提高系统的熵
......
pid = get_task_pid(p, PIDTYPE_PID); // 分配一个pid给当前进程
nr = pid_vnr(pid);
......
if (clone_flags & CLONE_VFORK) { // 分配vfork工作
p->vfork_done = &vfork;
init_completion(&vfork);
get_task_struct(p);
}
if (IS_ENABLED(CONFIG_LRU_GEN) && !(clone_flags & CLONE_VM)) { // 处理一下进程lru的相关数据
/* lock the task to synchronize with memcg migration */
task_lock(p);
lru_gen_add_mm(p->mm);
task_unlock(p);
}
wake_up_new_task(p); // 唤醒当前进程
......
put_pid(pid);
return nr;
}
copy_process的流程很长,就不一一分析了,其中主要流程如下:
- 首先,函数会检查
clone_flags中的一些标志,以确定新进程的一些属性。例如,如果设置了CLONE_NEWNS和CLONE_FS标志,新进程将在新的命名空间中,并且与父进程共享文件系统。 - 然后,函数会创建一个新的
task_struct结构体实例,这个结构体用于表示新的进程。新进程的所有信息都将存储在这个结构体中。 - 接着,函数会复制父进程的各种属性到新进程中。这包括进程的凭据(如用户ID和组ID)、资源限制、文件描述符表、文件系统上下文、信号处理函数、内存管理结构、命名空间等。
- 然后,函数会对新进程进行一些初始化操作,例如设置进程的状态、初始化进程的计时器、设置进程的父进程和子进程列表等。
- 在所有这些操作完成之后,新进程将被添加到系统的进程列表中,这使得它可以被系统的调度器看到并且开始运行。
- 最后,如果所有操作都成功完成,
copy_process函数将返回一个指向新进程的task_struct结构体的指针。如果在创建新进程的过程中发生错误,函数将返回一个错误指针。
在kernel_clone其中vfork的一个区别操作是填充vfork_done结构体,用来标识vfork操作完成。
if (clone_flags & CLONE_VFORK) { // 分配vfork工作
p->vfork_done = &vfork;
init_completion(&vfork);
get_task_struct(p);
}
如果包含,那么就设置新进程的vfork_done字段为&vfork,这个字段用于指示vfork操作何时完成。然后,调用init_completion函数初始化vfork完成变量,这个函数将完成变量的状态设置为未完成。
问题:fork复制了新的内存空间,那有哪些具体的内存或者资源被复制了。
例如在copy_mm中,如果是vfork,则把当前的mm结构体指向父进程的。
if (clone_flags & CLONE_VM) {
mmget(oldmm);
mm = oldmm;
} else {
mm = dup_mm(tsk, current->mm);
if (!mm)
return -ENOMEM;
}
另外,copy_namespaces如果是vfork的话也不会执行相关的逻辑,而是直接返回。
1.4-clone3
另外还有一个下列常用的sys_call,clone3可以看作是更精细的fork操作。允许细粒度控制子进程的属性,包括内存共享、信号处理等。因此,更适合于需要复杂进程管理的现代应用,如容器和虚拟化。
SYSCALL_DEFINE2(clone3, struct clone_args __user *, uargs, size_t, size)
{
int err;
struct kernel_clone_args kargs;
pid_t set_tid[MAX_PID_NS_LEVEL];
kargs.set_tid = set_tid;
err = copy_clone_args_from_user(&kargs, uargs, size); // 在系统调用时,我们可以指定传参clone_flags
if (err)
return err;
if (!clone3_args_valid(&kargs))
return -EINVAL;
return kernel_clone(&kargs); // 按照用户态定义的clone_flags来执行进程复制操作。
}
2、创建一个全新进程
当在用户态执行./bin的时候就会调用到execve的系统调用进程进程的创建。
内核中通过fs/exec.c中的函数创建一个全新的进程,而不是通过复制的方式。 execve()系统调用用于在新创建的进程中加载并执行一个新程序,替换当前进程的地址空间。
SYSCALL_DEFINE3(execve,
const char __user *, filename,
const char __user *const __user *, argv,
const char __user *const __user *, envp)
{
return do_execve(getname(filename), argv, envp);
}
经过一系列的调用,最终会通过bprm_execve来创建新的进程。
/*
* sys_execve() executes a new program.
*/
static int bprm_execve(struct linux_binprm *bprm,
int fd, struct filename *filename, int flags)
{
struct file *file;
int retval;
retval = prepare_bprm_creds(bprm); // 准备新进程的凭证(如UID、GID等)
if (retval)
return retval;
/*
* Check for unsafe execution states before exec_binprm(), which
* will call back into begin_new_exec(), into bprm_creds_from_file(),
* where setuid-ness is evaluated.
*/
check_unsafe_exec(bprm);
current->in_execve = 1; // 标记当前进程正在执行execve
sched_mm_cid_before_execve(current);
file = do_open_execat(fd, filename, flags); // open当前的文件
......
sched_exec();
......
/* Set the unchanging part of bprm->cred */
retval = security_bprm_creds_for_exec(bprm); // 检查要执行进程的安全性,例如selinux
......
retval = exec_binprm(bprm); // 执行二进制,创建进程
......
/* 执行成功后,要重置一下进程的统计信息 */
current->fs->in_exec = 0;
current->in_execve = 0;
rseq_execve(current);
user_events_execve(current);
acct_update_integrals(current);
task_numa_free(current, false);
return retval;
......
}
而exec_binprm则中会调用search_binary_handler来搜索当前二进制的执行方法,例如如果是elf二进制则调用load_elf_binary,而在其中则会设置二进制的入口函数e_entry = elf_ex->e_entry + load_bias;,并且也会做好内存空间的准备
static int load_elf_binary(struct linux_binprm *bprm)
{
...
/* 获取ELF头部信息 */
elf_ex = (struct elfhdr *)bprm->buf;
/* 检查ELF头部的有效性 */
if (memcmp(elf_ex->e_ident, ELFMAG, SELFMAG) != 0)
return -ENOEXEC;
/* 读取程序头表 */
elf_phdata = load_elf_phdrs(elf_ex, bprm->file);
if (!elf_phdata)
return -ENOMEM;
/* 设置程序的内存布局 */
for (i = 0; i < elf_ex->e_phnum; i++) {
struct elf_phdr *elf_ppnt = &elf_phdata[i];
if (elf_ppnt->p_type == PT_LOAD) {
error = elf_load_segment(bprm->file, bprm->vma, elf_ppnt, ...);
...
if (!load_addr_set) {
load_addr_set = 1;
load_addr = elf_ppnt->p_vaddr - elf_ppnt->p_offset;
}
}
...
}
/* 设置二进制的bss和brk */
elf_bss = ...;
elf_brk = ...;
/* 设置开始和结束代码/数据地址 */
start_code = ...; end_code = ...;
start_data = ...; end_data = ...;
/* 设置进程的入口点 */
bprm->p = arch_align_stack(bprm->p);
bprm->exec = bprm->p;
retval = setup_arg_pages(bprm, ...);
...
install_exec_creds(bprm);
...
set_binfmt(&elf_format);
/* 设置新的堆栈 */
retval = setup_new_exec(bprm);
...
/* 更新当前进程的信息 */
current->mm->start_code = start_code;
current->mm->end_code = end_code;
current->mm->start_data = start_data;
current->mm->end_data = end_data;
current->mm->start_brk = current->mm->brk = elf_brk;
current->mm->start_stack = bprm->p;
/* 设置进程的入口地址 */
current->mm->start_stack = bprm->p;
retval = arch_setup_additional_pages(bprm, ...);
...
start_thread(regs, elf_ex->e_entry, bprm->p); // 开始准备在用户态执行进程,这个函数是跟架构有关的
...
return 0;
}
而start_thread则最会调用到start_thread_common,最终设置用户态进程的函数指针,从而在切回用户态时,开始执行我们加载的二进制文件。
static void
start_thread_common(struct pt_regs *regs, unsigned long new_ip,
unsigned long new_sp,
unsigned int _cs, unsigned int _ss, unsigned int _ds)
{
WARN_ON_ONCE(regs != current_pt_regs());
if (static_cpu_has(X86_BUG_NULL_SEG)) {
/* Loading zero below won't clear the base. */
loadsegment(fs, __USER_DS);
load_gs_index(__USER_DS);
}
reset_thread_features();
loadsegment(fs, 0);
loadsegment(es, _ds);
loadsegment(ds, _ds);
load_gs_index(0);
/*更新函数的指针地址,保证切回用户态时会执行新进程(二进制文件)*/
regs->ip = new_ip;
regs->sp = new_sp;
regs->cs = _cs;
regs->ss = _ss;
regs->flags = X86_EFLAGS_IF;
}
3、进程销毁
3.1-exit
我们在用户态中经常通过exit()函数来实现进程的退出,这个sys_call被定义在了kernel/exit.c,因此exit使用来结束自己身进程的。
SYSCALL_DEFINE1(exit, int, error_code)
{
do_exit((error_code&0xff)<<8);
}
进程主动退出的时候,会执行do_exit相关逻辑,这里会主动处理掉进程在linux kernel中的相关资源,值得注意的是这是一个noreturn的函数。
void __noreturn do_exit(long code)
{
struct task_struct *tsk = current;
int group_dead;
WARN_ON(irqs_disabled()); // 在中断执行过程中关闭中断,避免流程被打断。
synchronize_group_exit(tsk, code); // 处理进程组的退出同步
......
coredump_task_exit(tsk); // 转存当前进程的coredump
......
exit_signals(tsk); /* 用来处理退出信号 */
.....
group_dead = atomic_dec_and_test(&tsk->signal->live);
if (group_dead) { // 如果一个group之中的所有进程都消亡了,就做更多的事情
......
#ifdef CONFIG_POSIX_TIMERS
hrtimer_cancel(&tsk->signal->real_timer); // 取消定时器
exit_itimers(tsk);
#endif
if (tsk->mm)
setmax_mm_hiwater_rss(&tsk->signal->maxrss, tsk->mm); // 增加内存最大的rss
}
......
taskstats_exit(tsk, group_dead); // 在退出时收集任务统计信息
exit_mm(); // 退出内存
......
exit_sem(tsk); // 释放进程使用的信号量
exit_shm(tsk); // 释放进程使用的共享内存
exit_files(tsk);// 释放进程使用的文件描述符
exit_fs(tsk);// 释放进程使用的文件系统
if (group_dead)
disassociate_ctty(1); // 取消进程的controlling tty
exit_task_namespaces(tsk); // 释放进程的命名空间
exit_task_work(tsk); // 处理进程绑定的task_work
exit_thread(tsk); // 处理线程相关的工作
......
flush_ptrace_hw_breakpoint(tsk); // 清除硬件断点
.....
exit_notify(tsk, group_dead); // 通知其他进程这个进程已经退出,并且会通知父进程绑定好的task->sig
proc_exit_connector(tsk); // 发送进程退出的连接器事件
mpol_put_task_policy(tsk); // 释放进程的内存策略
......
debug_check_no_locks_held(); // 检查当前有没有持锁被异常释放了
if (tsk->io_context)
exit_io_context(tsk); // 释放进程的io资源
if (tsk->splice_pipe)
free_pipe_info(tsk->splice_pipe); // 释放进程的splice管道
if (tsk->task_frag.page)
put_page(tsk->task_frag.page); // 释放进程的任务片段页
validate_creds_for_do_exit(tsk); // 验证进程的`creds`
exit_task_stack_account(tsk);
check_stack_usage(); // 检查栈的使用情况
preempt_disable(); // 禁止内核抢占
if (tsk->nr_dirtied) // 如果进程有脏页
__this_cpu_add(dirty_throttle_leaks, tsk->nr_dirtied); // 添加到当前CPU的dirty_throttle_leaks计数,方便后续回收
exit_rcu();
exit_tasks_rcu_finish();
lockdep_free_task(tsk); // 释放进程的锁依赖信息
do_task_dead(); // 将当前进标记为已死亡(TASK_DEAD)
}
这里值得一提的是creds(即凭据)是一个表示进程安全属性的结构,包含了进程的用户ID、组ID、附加组ID、安全能力等信息。这些信息用于决定进程可以访问哪些资源以及执行哪些操作。
而do_exit通过调用exit_notify中的do_notify_parent用SIG通过父进程子进程已经消亡了。
3.2-wait4
另外还有一个wait4,是父进程用来调用,等待子进程消亡,也就是我们之前说到的由父进程为子进程进行收尸。
SYSCALL_DEFINE4(wait4, pid_t, upid, int __user *, stat_addr,
int, options, struct rusage __user *, ru)
{
struct rusage r;
long err = kernel_wait4(upid, stat_addr, options, ru ? &r : NULL);
if (err > 0) {
if (ru && copy_to_user(ru, &r, sizeof(struct rusage)))
return -EFAULT;
}
return err;
}
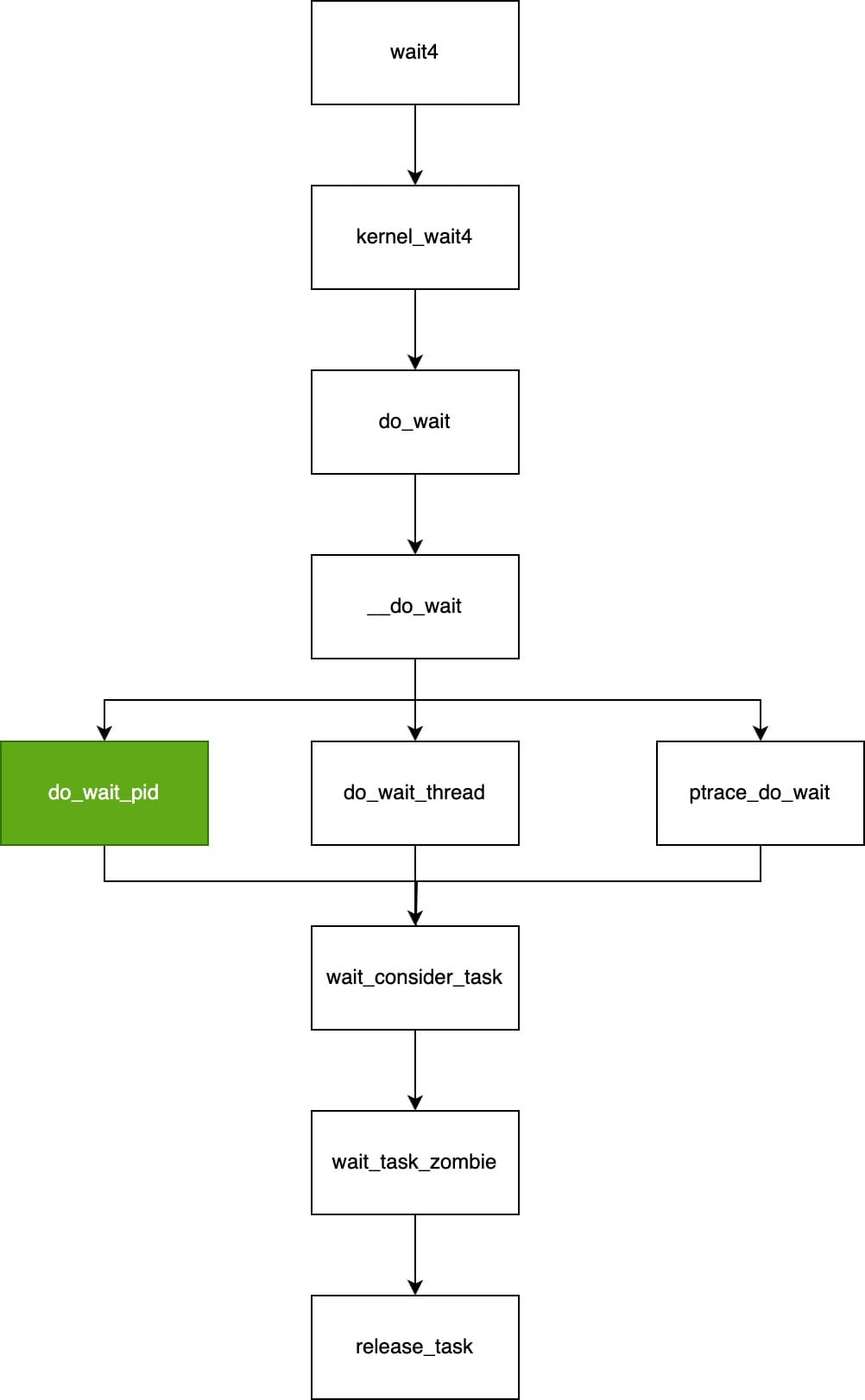
而wait4->kernel_wait4->do_wait->__do_wait->do_wait_pid->wait_consider_task->wait_task_zombie->release_task,按照上述流程调用,最终释放掉task_struct结构体。
static long do_wait(struct wait_opts *wo)
{
int retval;
trace_sched_process_wait(wo->wo_pid);
init_waitqueue_func_entry(&wo->child_wait, child_wait_callback); // 初始化一个waitqueue
wo->child_wait.private = current;
add_wait_queue(¤t->signal->wait_chldexit, &wo->child_wait); // 把自己加入到这个队列上
do {
set_current_state(TASK_INTERRUPTIBLE);
retval = __do_wait(wo); // 进入循环等待
if (retval != -ERESTARTSYS)
break;
if (signal_pending(current)) // 父进程如果有其他信号处理,则退出
break;
schedule(); // 等待的时候让出调度
} while (1); // 循环等待子进程消亡
__set_current_state(TASK_RUNNING);
remove_wait_queue(¤t->signal->wait_chldexit, &wo->child_wait);
return retval;
}
再wait4中会将类型设置为PIDTYPE_TGID,因此最终会调用do_wait_pid。
另外如果父进程没有显示的调用wait4等等处理函数,则会在信号处理的流程中处理消亡进程发送过来的信号,并对子进程的"遗体"进行处理,个人理解,父进程可以绑定一个SIGCHLD的处理器,这样当父进程接到信号SIGCHLD的时候就会调用类似于wait4的api对子进程进行处理。类似于exit_to_user_mode_loop中
static unsigned long exit_to_user_mode_loop(struct pt_regs *regs,
unsigned long ti_work)
{
......
if (ti_work & (_TIF_SIGPENDING | _TIF_NOTIFY_SIGNAL))
arch_do_signal_or_restart(regs); // 如果有信号,则处理下这个信号
......
}
另外还有中断返回时也会处理信号量,信号处理的详细流程可以参考以后的信号量分析。
3.3-二者区别
- 作用对象
exit: 由当前进程调用,用于结束自身。wait4: 由父进程调用,用于等待子进程结束。
- 作用结果
exit: 导致调用它的进程结束。wait4: 并不结束任何进程,而是等待其他进程结束。
- 进程间通信
exit提供了一种通过退出状态与父进程通信的方式。wait4使父进程能够获取子进程的退出状态。
- 资源管理
exit触发资源的释放。wait4确保这些资源被系统回收。