CPU虚拟化

1、CPU虚拟化概述
CPU虚拟化是一种技术,它允许单个物理CPU模拟多个虚拟CPU(VCPU)。这使得多个操作系统(OS)实例能够在同一个物理服务器上并行运行,每个实例都在自己的隔离环境中执行。在虚拟化环境中,操作系统通常运行在被称为虚拟机(VM)的封装环境中。每个VM都像拥有独立的物理硬件一样运行,尽管实际上它们共享着同一台物理机的资源。
1.1-虚拟化技术的关键挑战
- 特权指令和敏感操作:在没有硬件支持的情况下,CPU虚拟化的主要挑战之一是处理特权指令。这些指令通常只能由物理CPU上的最高权限级别执行,例如,直接访问硬件资源。在虚拟环境中,当虚拟机试图执行这些指令时,必须有一种机制来适当地处理它们,以避免对系统的安全和稳定性造成影响。现代CPU通常存在
ring0~ring34个级别,而在linux与windows则只使用ring0与ring3两个级别,通常来说,用户态的代码运行在ring3中,而内核态的代码运行在ring0中,任何直接与硬件交互、管理系统资源的操作都是在ring0下执行的。通常,当CPU在ring3中尝试执行ring0级别操作时,会抛出一个CPU异常,而此时VMM则会捕获这个异常,代替用户态的虚拟机执行该命令。然而在x86平台上不是所有的命令都会抛出异常,有一些敏感指令并不是特权指令,比如在用户态修改中断状态(IF)寄存器,如果在用户态执行该命令,CPU则只会忽略该命令。- 特权指令(Privileged Instructions):
- 特权指令是那些只能在处理器的最高特权级别(通常是Ring 0,在x86体系结构中被称为内核模式)下运行的指令。
- 这些指令通常用于执行系统级的操作,如管理硬件设备、改变内存访问权限、控制CPU的状态等。
- 特权指令的执行通常是受操作系统内核控制的。当用户空间的应用程序需要执行这些操作时,它们会通过系统调用的形式委托给内核执行。
- 敏感指令(Sensitive Instructions):
- 敏感指令是那些对系统的全局状态或资源有影响的指令,这包括特权指令和非特权指令。
- 敏感指令的范围更广,不仅包括改变或查询处理器模式、硬件配置或其他系统资源的指令,也包括那些可能改变系统的控制流、中断处理或数据流的指令。
- 特权指令(Privileged Instructions):
- 资源共享和隔离:虚拟化环境必须确保所有虚拟机可以高效、公平地共享CPU资源,同时保持彼此的隔离,以避免一个虚拟机的操作影响到其他虚拟机。
1.2-虚拟化技术的发展
- 软件模拟:早期的CPU虚拟化技术,如Bochs和QEMU,使用纯粹的软件模拟来处理特权指令,这种方法的缺点是性能开销较大。另外通常在在
A架构上执行B架构虚拟机原理也是模拟。 - 动态二进制翻译:VMware使用了一种称为动态二进制翻译(DBT)的技术,它在运行时将特权指令转换为不同的指令序列,以在虚拟化环境中正确执行。我们上问题所提到的一种解决
x86平台特权指令的方案就是动态翻译。 - 硬件辅助虚拟化:随后,处理器制造商如Intel和AMD在其CPU中引入了硬件辅助虚拟化技术(例如Intel的VT-x和AMD的AMD-V)。这些技术通过在硬件层面提供对虚拟化的支持,允许虚拟机可以直接执行ring0的代码,这种方案无须对命令进行转译而直接执行命令,故而显著提高了性能和效率。
1.3-虚拟机监控器(VMM)
- 定义和作用:虚拟机监控器(VMM)是虚拟化技术中的核心组件。它负责管理虚拟机的资源分配、调度和执行。在硬件辅助的虚拟化环境中,VMM通常运行在更高的权限级别,以便控制对硬件的访问和管理虚拟机的执行。
- VMM的类型:VMM可以是类型一(运行在裸机上)或类型二(运行在宿主操作系统之上)。KVM(Kernel-based Virtual Machine)是一种类型一VMM,而QEMU通常作为类型二VMM使用。
2、硬件辅助虚拟化
2.1-硬件辅助虚拟化的实现
如果想要实现CPU的硬件虚拟化,我们则需要CPU具备一下能力:
- CPU指令集支持:硬件辅助虚拟化需要CPU支持一组特殊的指令集。这些指令用于管理虚拟机的创建、执行、暂停和销毁。
- 上下文切换:硬件辅助虚拟化技术允许快速有效地在虚拟机和宿主机环境之间进行上下文切换。这使得虚拟机可以在接近原生性能的情况下运行。
2.2-VMX
Intel开发了一种VT技术以支持虚拟化,为CPU虚拟化增加了一个叫做Virtual-Machine Extensions(VMX)的功能。
VT中的VMX root模式和non-root模式分别用于虚拟机监控器(VMM)和虚拟机(VM)。这种情况下,则可以使虚拟机的内核直接运行在CPU的ring0,也就避免的特权、敏感指令的相关问题,而虚拟机的用户态则继续维持在ring3状态下,保证了系统的安全。
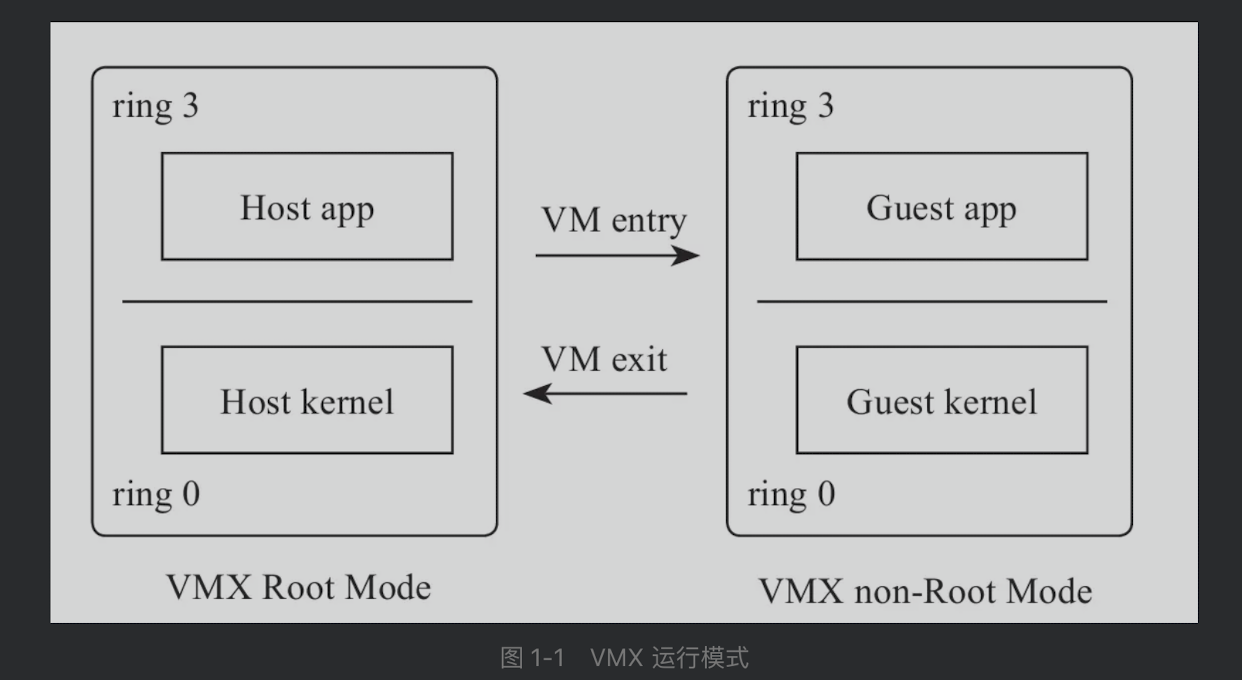
2.2.1-进入虚拟机
运行在ROOT Mode中的VMM第一次将通过VMLaunch命令将CPU状态切换到non-Root Mode,执行进入Guest的VM entry操作。而后续VMM则会通过VMResume命令重新进入到non-Root Mode。通过kvm_arch_vcpu_ioctl_run的ioctl实现用户态的调用。
static fastpath_t vmx_vcpu_run(struct kvm_vcpu *vcpu)
{
......
/* 检查是否可以进入虚拟机,如果不需要的话则直接退出 */
if (unlikely(vmx->emulation_required)) {
vmx->fail = 0;
......
return EXIT_FASTPATH_NONE;
}
trace_kvm_entry(vcpu);
......
/* 获取HOST中CR3、CR4寄存器状态 */
cr3 = __get_current_cr3_fast();
......
cr4 = cr4_read_shadow();
......
/* 执行VMLAUNCH或者VMRESUME,并在完成后退出 */
vmx_vcpu_enter_exit(vcpu, __vmx_vcpu_run_flags(vmx));
/* 后边主要是虚拟机退出后,代码会执行一系列清理和状态同步操作 */
if (kvm_is_using_evmcs()) {
current_evmcs->hv_clean_fields |=
HV_VMX_ENLIGHTENED_CLEAN_FIELD_ALL;
current_evmcs->hv_vp_id = kvm_hv_get_vpindex(vcpu);
}
......
if (unlikely(vmx->fail))
return EXIT_FASTPATH_NONE;
if (unlikely((u16)vmx->exit_reason.basic == EXIT_REASON_MCE_DURING_VMENTRY))
kvm_machine_check();
/* 完成vcpu生命周期后则会退出虚拟机 */
trace_kvm_exit(vcpu, KVM_ISA_VMX);
.....
if (is_guest_mode(vcpu))
return EXIT_FASTPATH_NONE;
return vmx_exit_handlers_fastpath(vcpu);
}
上边的函数最终会调用到arch/x86/kvm/vmx/vmenter.S中的__vmx_vcpu_run的汇编函数进入到虚拟机中,并通过传参flag判断具体是resume还是launch。
/**
* __vmx_vcpu_run - Run a vCPU via a transition to VMX guest mode
* @vmx: struct vcpu_vmx *
* @regs: unsigned long * (to guest registers)
* @flags: VMX_RUN_VMRESUME: use VMRESUME instead of VMLAUNCH
* VMX_RUN_SAVE_SPEC_CTRL: save guest SPEC_CTRL into vmx->spec_ctrl
*
* Returns:
* 0 on VM-Exit, 1 on VM-Fail
*/
2.2.2-退出虚拟机
而如果guest内核中执行部分特权命令(如I/O访问)时,则会触发CPU陷入的动作,此时则会退出guest VM exit,CPU则从non-Root Mode切换回root Mode,然后VMM则捕获这些特权命令,由其模拟该命令,代替虚拟机内核执行。造成VM Exit的常见情况包括访问I/O端口、处理外部中断等。
退出的实际操作在vmx_vcpu_run中,并且会根据不同的退出原因执行对应的逻辑。
static fastpath_t vmx_exit_handlers_fastpath(struct kvm_vcpu *vcpu)
{
switch (to_vmx(vcpu)->exit_reason.basic) {
case EXIT_REASON_MSR_WRITE:
return handle_fastpath_set_msr_irqoff(vcpu);
case EXIT_REASON_PREEMPTION_TIMER:
return handle_fastpath_preemption_timer(vcpu);
default:
return EXIT_FASTPATH_NONE;
}
}
其中退出的原因分析如下
EXIT_REASON_MSR_WRITE:- 当虚拟机尝试写入一个模型特定寄存器(MSR)时,会触发此类VM Exit。
handle_fastpath_set_msr_irqoff函数处理这种类型的VM Exit,它会快速响应MSR写操作。这通常涉及到更新虚拟机的MSR值,而不需要复杂的模拟或状态更新。这种处理通常比完全模拟MSR写操作更高效。
EXIT_REASON_PREEMPTION_TIMER:- 当VMX预处理计时器到期时,会触发这种VM Exit。
handle_fastpath_preemption_timer函数处理这种类型的VM Exit,它通常涉及到更新虚拟机的计时器状态或调度信息。这可以用于确保虚拟机不会占用过多的宿主CPU时间,从而允许宿主操作系统更公平地分配处理器资源给其他任务。
而KVM模块中的handle_exit以及__vmx_handle_exit只是用来处理已经退出的虚拟机后续状态,而不是直接执行退出的实际逻辑。通过上述逻辑大概也可以看到,虚拟机退出时主要是被动退出,而不是类似于进入时的主动调用。
static int vmx_handle_exit(struct kvm_vcpu *vcpu, fastpath_t exit_fastpath)
{
int ret = __vmx_handle_exit(vcpu, exit_fastpath);
......
return ret;
}
2.2.3-vcpu上下文
VMCS(Virtual Machine Control Structure):在VT-x中,VMCS是用来保存虚拟机的状态和控制虚拟机执行的数据结构。每个VCPU都有一个对应的VMCS,它包含了关于VCPU的执行状态、控制字段和其他管理信息。
在v6.6中被定义在了arch/x86/kvm/vmx/vmcs.h,主要包含以下几个结构体
struct vmcs_hdr {
u32 revision_id:31; // VMCS数据结构的版本号,用于确保VMCS的兼容性
u32 shadow_vmcs:1; // 指示是否使用影子VMCS,用于嵌套虚拟化
};
struct vmcs {
struct vmcs_hdr hdr; // 包含VMCS头部信息
u32 abort; // 如果VMCS操作失败,此字段被设置
char data[]; // 动态大小的数组,用于存储VMCS数据
};
DECLARE_PER_CPU(struct vmcs *, current_vmcs); // 每个CPU核心的当前VMCS指针
struct vmcs_host_state {
unsigned long cr3; // 宿主机的CR3寄存器值,可能与实际的CR3不同
unsigned long cr4; // 宿主机的CR4寄存器值,可能与实际的CR4不同
unsigned long gs_base; // GS段的基址
unsigned long fs_base; // FS段的基址
unsigned long rsp; // 宿主机的栈指针
u16 fs_sel, gs_sel, ldt_sel; // FS、GS和LDT的选择子
#ifdef CONFIG_X86_64
u16 ds_sel, es_sel; // DS和ES的选择子(仅在x86_64体系结构中)
#endif
};
struct vmcs_controls_shadow {
u32 vm_entry; // VM Entry相关的控制字段
u32 vm_exit; // VM Exit相关的控制字段
u32 pin; // 处理器相关的控制字段
u32 exec; // 执行控制字段
u32 secondary_exec; // 辅助执行控制字段
u64 tertiary_exec; // 第三级执行控制字段(如果可用)
};
struct loaded_vmcs {
struct vmcs *vmcs; // 指向当前VMCS的指针
struct vmcs *shadow_vmcs; // 指向影子VMCS的指针(用于嵌套虚拟化)
int cpu; // VMCS所在的CPU编号,如果未加载则为-1
bool launched; // 指示VMCS是否已经被VMLAUNCH指令启动
bool nmi_known_unmasked; // 指示NMI(非屏蔽中断)是否已知为未屏蔽
bool hv_timer_soft_disabled; // 指示是否软禁用了虚拟化定时器
int soft_vnmi_blocked; // 支持没有vnmi的CPU,记录vnmi被软屏蔽的状态
ktime_t entry_time; // 记录进入虚拟机的时间点
s64 vnmi_blocked_time; // vnmi被屏蔽的持续时间
unsigned long *msr_bitmap; // 指向MSR位图的指针
struct list_head loaded_vmcss_on_cpu_link; // 链接到同一CPU上的其他VMCS
struct vmcs_host_state host_state; // 宿主机状态的缓存
struct vmcs_controls_shadow controls_shadow; // 控制字段的阴影副本
};
2.2.4-总结
具备VMX的CPU相比如其他CPU具有如下特点:
- 虚拟机的系统调用是直接陷入的guest内核空间,而不是host的内核空间。
- 外部中断的实际处理仍有HOST内核完成,但是接收中断则是guest实现,guest完成接收后要退出虚拟机交由host内核进一步处理资源。(IO透传技术则会避免退出虚拟的问题)
- 只有敏感指令才会从
guest陷入host,由VMM代替虚拟机完成具体操作。
3、QEMU、KVM、libvirt、virsh之间的关系
3.1-具体介绍
- qemu
QEMU是一种开源的机器模拟器和虚拟化器。它可以模拟多种硬件,使得它可以在不同架构上运行各种操作系统。在不使用KVM的情况下,QEMU使用软件模拟来执行虚拟机中的指令。
- QEMU(Quick Emulator) 是一个开源的硬件虚拟化产品,它可以模拟各种硬件平台,允许用户在一个主机上运行多个操作系统。
- QEMU本身可以提供软件模拟的虚拟化,但当结合KVM使用时,可以利用硬件辅助,大大提高虚拟化的性能。
- KVM
KVM是Linux内核的一部分,它利用了硬件辅助虚拟化技术,特别是Intel的VT-x或AMD的AMD-V。当与QEMU结合使用时,KVM能够提供接近原生的性能,因为它允许直接在硬件上运行虚拟机的代码。
- KVM(Kernel-based Virtual Machine) 是一个Linux内核模块,它将Linux转变为一个类型1(裸机)的虚拟机监控器(Hypervisor)。
- KVM依赖于硬件虚拟化特性(如Intel VT或AMD-V),提供高效的虚拟化解决方案。
- KVM允许QEMU利用硬件加速功能,提高其虚拟化性能。
- libvirt
- libvirt 是一个开源的虚拟化API库,为管理虚拟化平台提供了一个通用和稳定的层。
- 它支持多种虚拟化技术,包括KVM、QEMU、Xen等。
- libvirt提供了一套统一的API来管理虚拟机和其他虚拟化资源,使得管理员可以透过统一的接口进行虚拟机的部署、监控和管理。
- virsh
- virsh(Virtualization Shell) 是一个基于命令行的工具,用于使用libvirt库来管理虚拟机和其他虚拟化资源。
- virsh允许用户执行各种虚拟化相关的任务,如创建、修改、启动和停止虚拟机。
- 它是一个与libvirt交互的前端工具,为用户提供了一个简单但功能强大的方式来管理虚拟化环境。
3.2 总结
KVM是集成在linux kernel中的一部分,他提供出了一些用户态的接口/dev/kvm来供用户态的进程管理虚拟机,但是其本身是不具备虚拟机模拟的能力的,因此内核基于qemu开发出了一套适配kvm的工具,也就是kvm-qemu,通过标准的文件操作例如open、write、ioctl等调用内核的KVM接口。所以可以看做qemu是是虚拟机的用户态工具,而qemu在CPU与内存虚拟化部分依赖KVM基于CPU平台硬件虚拟化所暴露出来的接口。
另外KVM只提供了内存和CPU的虚拟化能力,所以为了实现一个可用的计算机系统,还需要IO外设,例如网卡和硬盘,这部分能力则需要由qemu提供。
而libvirt则是用来统一各个虚拟化接口的库,virsh则是libvirt的命令行工具,即我们在命令行中执行的下令命令
virsh list
virsh create xxx
4、总结
虚拟化技术,在特别是CPU虚拟化领域,已经成为现代计算架构的一个基石。从早期的软件模拟到现在的硬件辅助虚拟化,它不断进化,提高了效率和安全性。通过像QEMU和KVM这样的工具,我们可以轻松地在单个物理机器上运行多个操作系统实例,极大地提高了资源的利用率和灵活性。
随着技术的不断发展,我们可以期待虚拟化技术在性能、安全性和易用性方面的进一步提升,为未来的计算模式铺平道路。